コード生成およびAgentic RAGタスクを中心とした特定ドメインのためのLLM比較評価【後編】


📖 読了時間:約25分
本記事は前後編の後編です。研究の背景・システムアーキテクチャ・実験設計については前編をご参照ください。後編では実験結果・パイプライン最適化・結論を取り扱います。
第4章 実験結果:コード生成タスク
本章では、NL to Pseudocode Agentのコード生成タスクに対する評価結果を提示する。伝統的テキスト指標とLLM-as-a-Judge評価結果を分析し、Thinkモードの影響とモデルの安定性を検討する。
全体品質評価結果
伝統的テキスト指標
表13は、主要モデルの伝統的テキスト指標の結果を要約したものである。
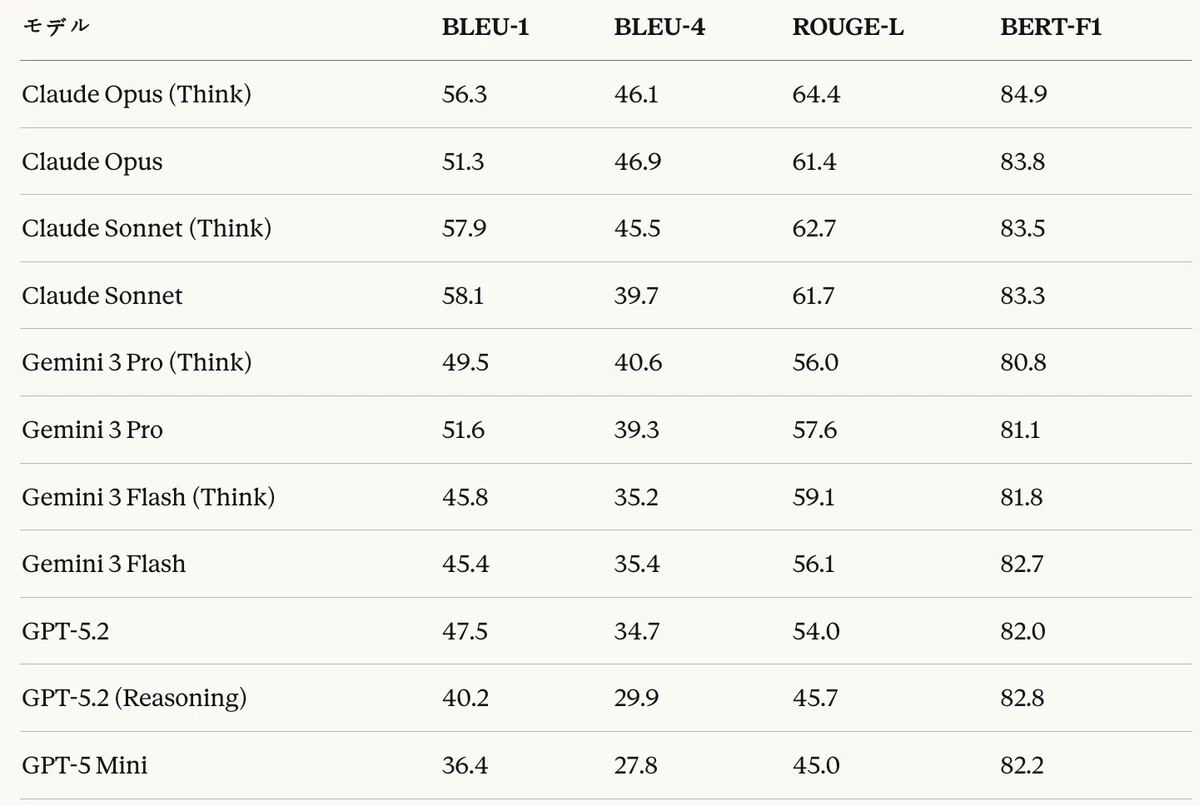
表13:コード生成タスク — 伝統的テキスト指標結果(%)
伝統的指標においてClaudeモデルが高い性能を記録した。ROUGE-LではClaude Opus(Think)が64.4%で最高スコアを記録し、BERT-F1においてもClaude Opus(Think)が84.9%で1位であった。GPTモデルはBLEU、ROUGE-Lでは低いスコアを示したものの、BERT-F1では他モデルと同等の水準を維持した。
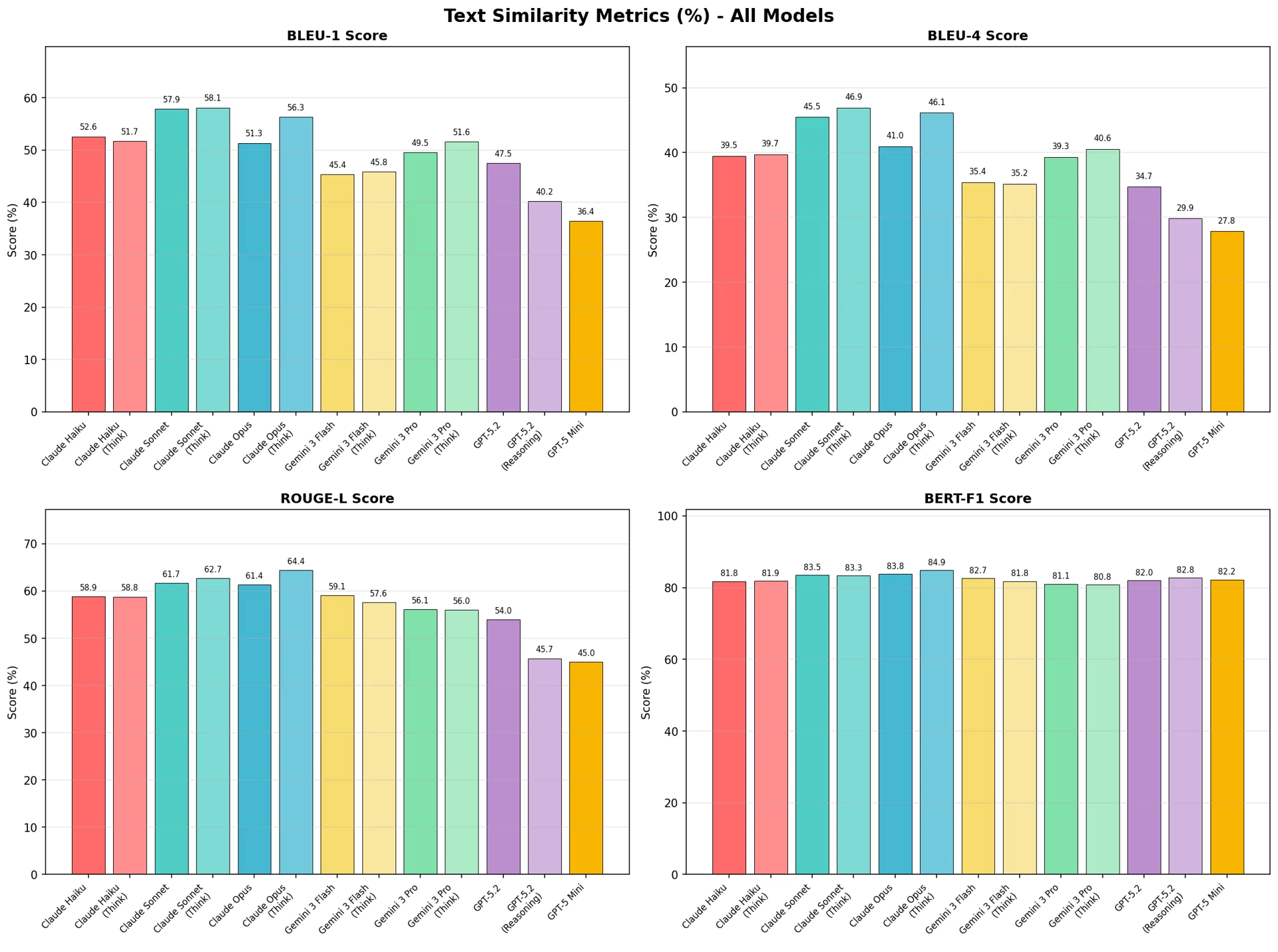
図5:テキスト類似度指標(%)— 全モデル比較
LLM-as-a-Judge評価結果
表14は、LLM-as-a-Judge評価結果を整理したものである。
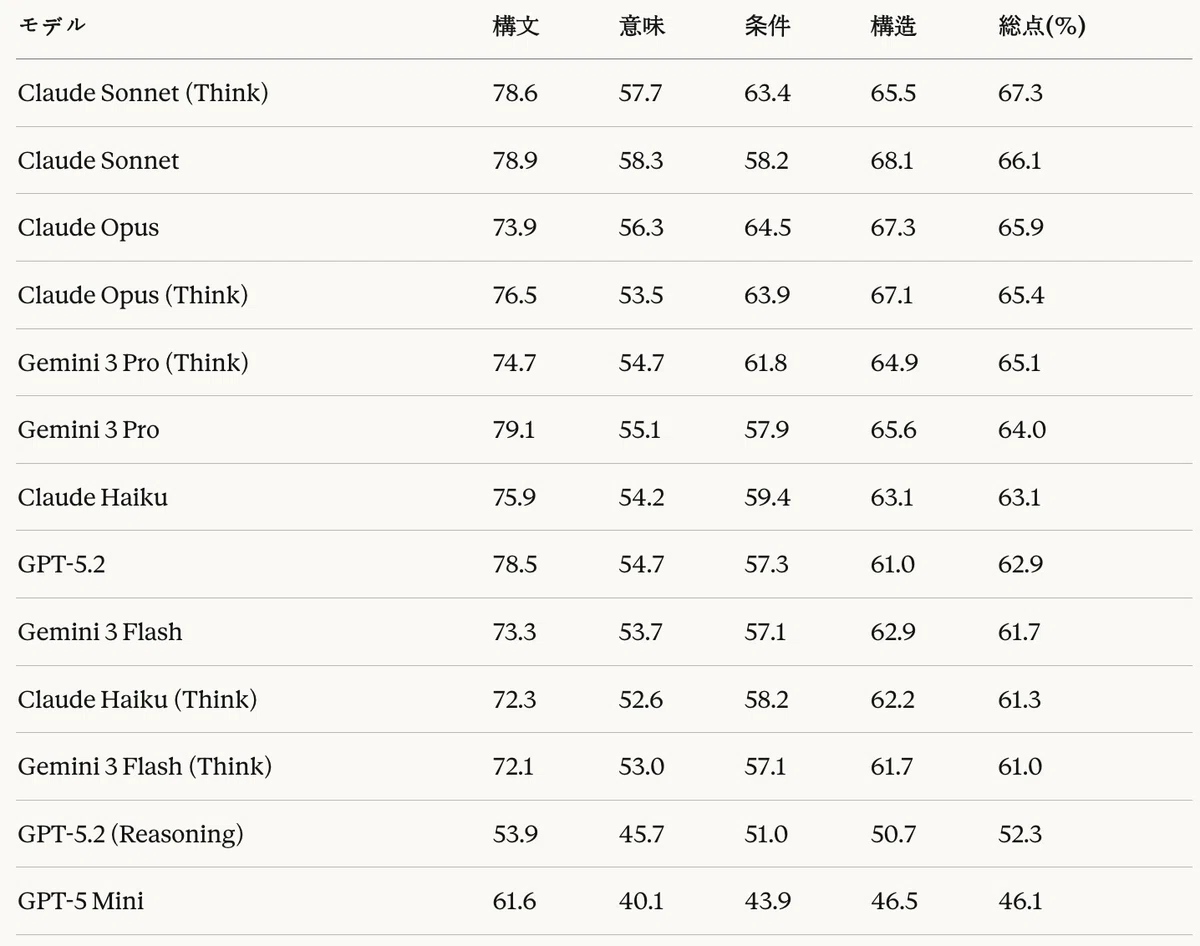
表14:コード生成タスク — LLM-as-a-Judge評価結果(正規化%)
LLM-as-a-Judge評価において、Claude Sonnet(Think) が67.3%で1位、Claude Opusが66.1%で2位を記録した。コスト効率的なモデルの中では、Gemini 3 Flashが61.7%を記録した。
次元別に分析すると、すべてのモデルが構文正確性において高いスコア(53.9〜79.1%)を記録した一方、意味等価性と条件完全性では中程度の水準(40.1〜58.3%)にとどまった。これは、モデルが文法的に正しいCTE構文の生成には長けているものの、参照コードと同一の意味や条件を捉えるのには限界があることを示唆している。
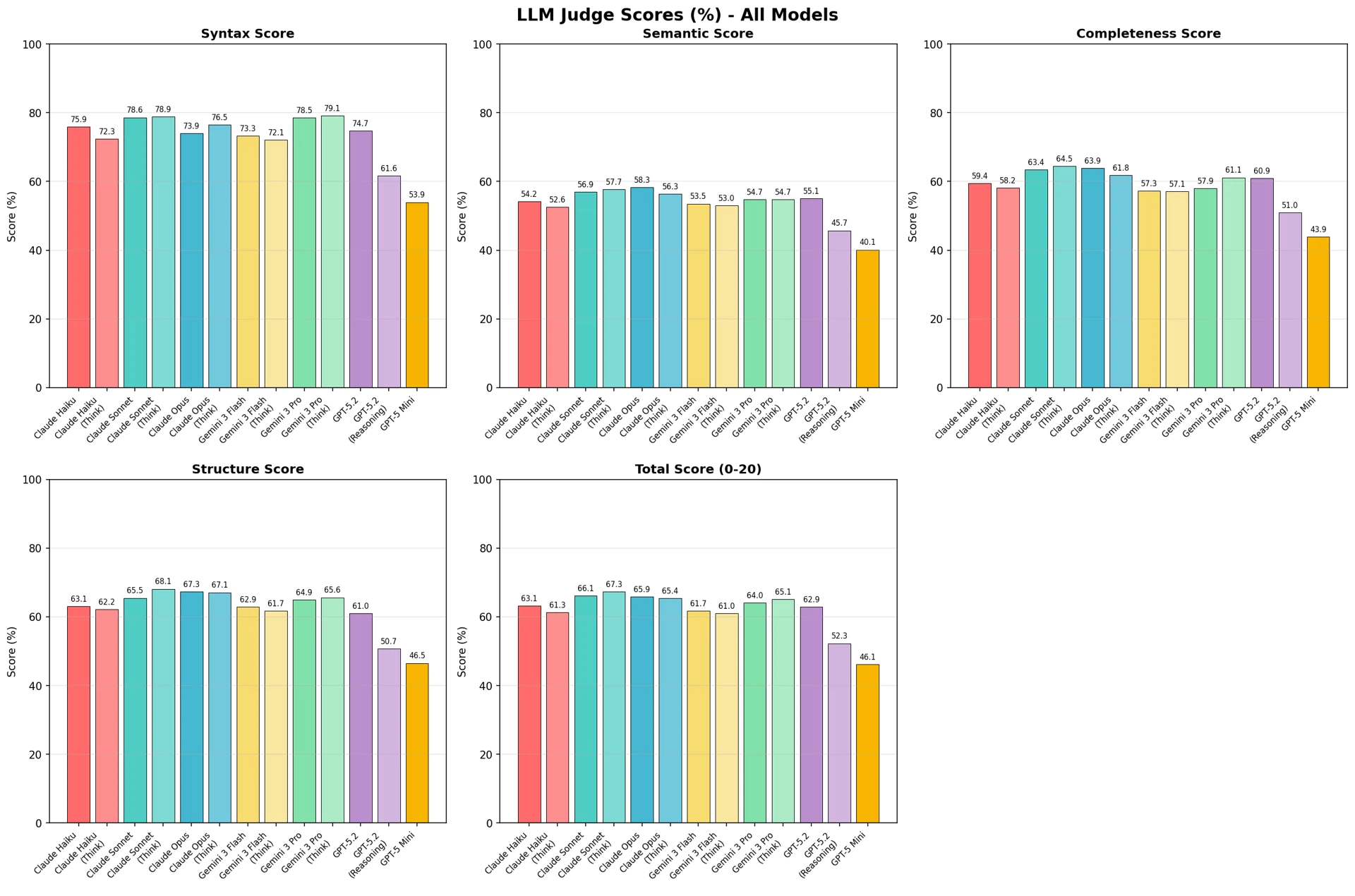
図6:LLM-as-a-Judgeスコア(%)— 全モデル比較
Thinkモード効果分析
Thinkモードのタスク別影響
表15は、各モデルにおけるThinkモード有効化に伴う性能変化を整理したものである。
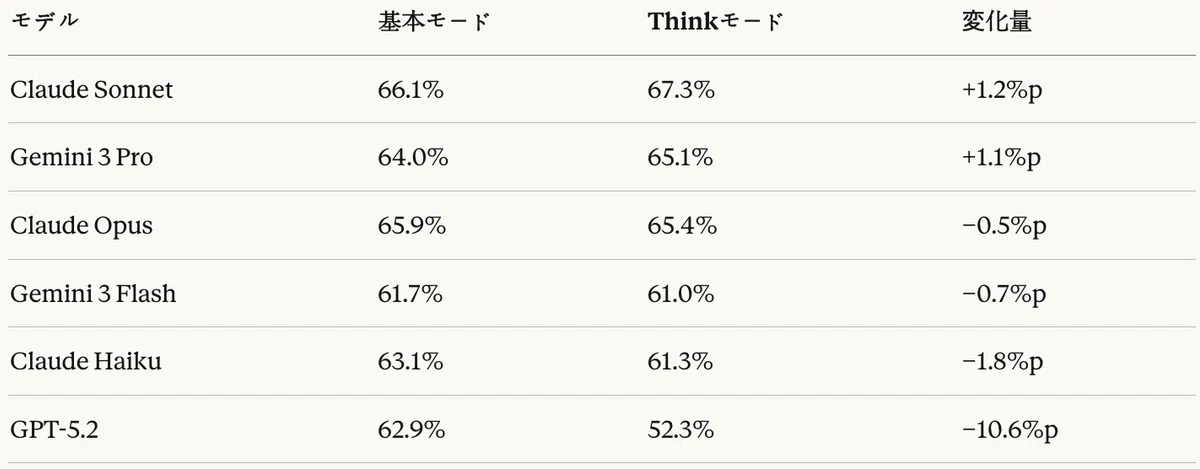
表15:コード生成タスク — Thinkモード効果(LLM-as-a-Judge総点基準)
コード生成タスクにおけるThinkモードの効果は、モデルによって異なる結果を示した。
肯定的効果
- Claude SonnetはThinkモードで+1.2%pの向上を記録し、全体1位(67.3%)を達成
- Gemini 3 Proも+1.1%pの改善
否定的効果
- Claude HaikuはThinkモードで−1.8%pの低下
- GPT-5.2はReasoningモードで−10.6%pの深刻な性能低下が発生
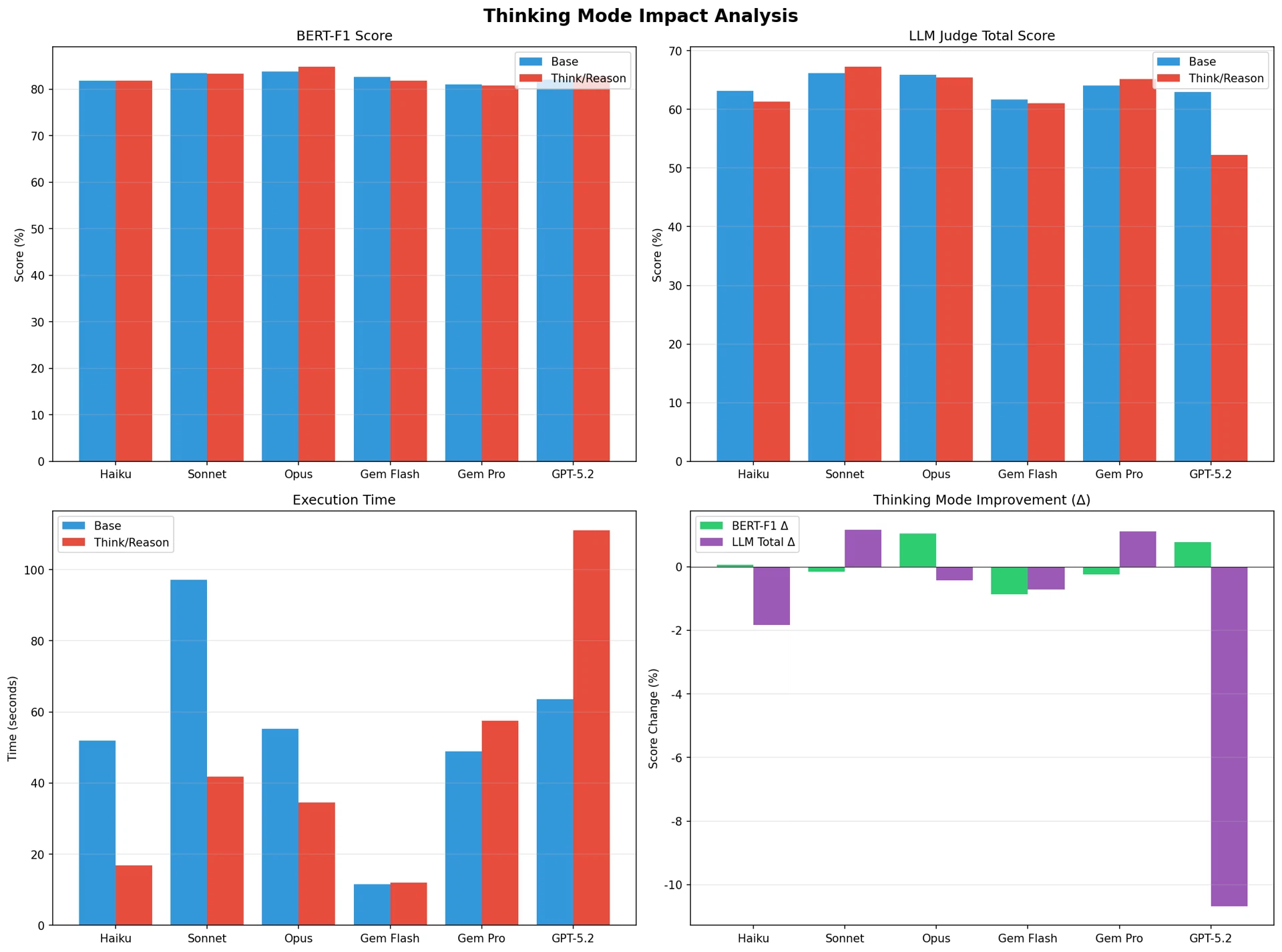
図7:Thinkingモード影響分析
Thinkモード効果の解釈
コード生成タスクにおいてClaude SonnetのExtended Thinkingが肯定的効果を記録した一方、GPTのReasoningモードは顕著な性能低下を記録した。これは以下のように解釈できる。
- タスク特性との適合性:コード生成は論理的構造化と正確な構文生成が重要なタスクであり、ClaudeのExtended Thinkingがこの要求事項に適合するよう設計されている可能性がある。
- 過度な推論の副作用:GPTのReasoningモードは複雑な数学的推論に最適化されているため、定型化されたコード生成タスクでは過度な推論がかえって阻害要因となり得る。
- 安定性の問題:GPT-5.2(Reasoning)は高い空応答率を示し、実質的な性能低下につながった。
モデル分析
空応答率(Empty Response Rate)
実際の運用環境においてモデルの安定性は品質に劣らず重要である。表16は安定性分析の結果を整理したものである。
具体的には、httpxクライアントのタイムアウトを300秒(5分)に設定し、当該時間内に応答を完了できなかった場合を「空応答」とみなして算出した。
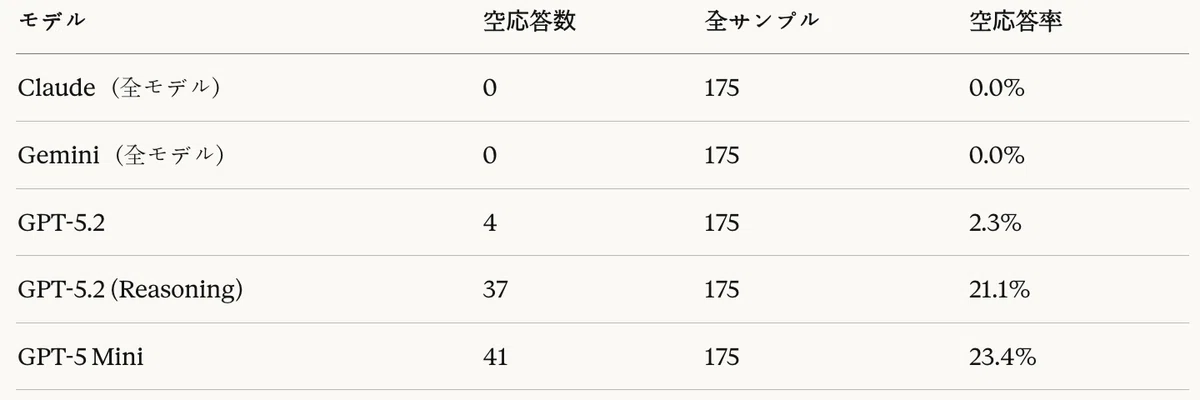
表16:コード生成タスク — モデル別空応答率
安定性分析の結果、ClaudeとGeminiモデルはいずれも0%の空応答率を記録し、完全な安定性を示した。一方、GPTモデルは深刻な安定性の問題を露呈した。
- GPT-5.2:2.3%(4/175)の空応答で注意が必要な水準
- GPT-5.2(Reasoning):21.1%(37/175)の空応答でプロダクション使用に不適合
- GPT-5 Mini:23.4%(41/175)の空応答でプロダクション使用に不適合
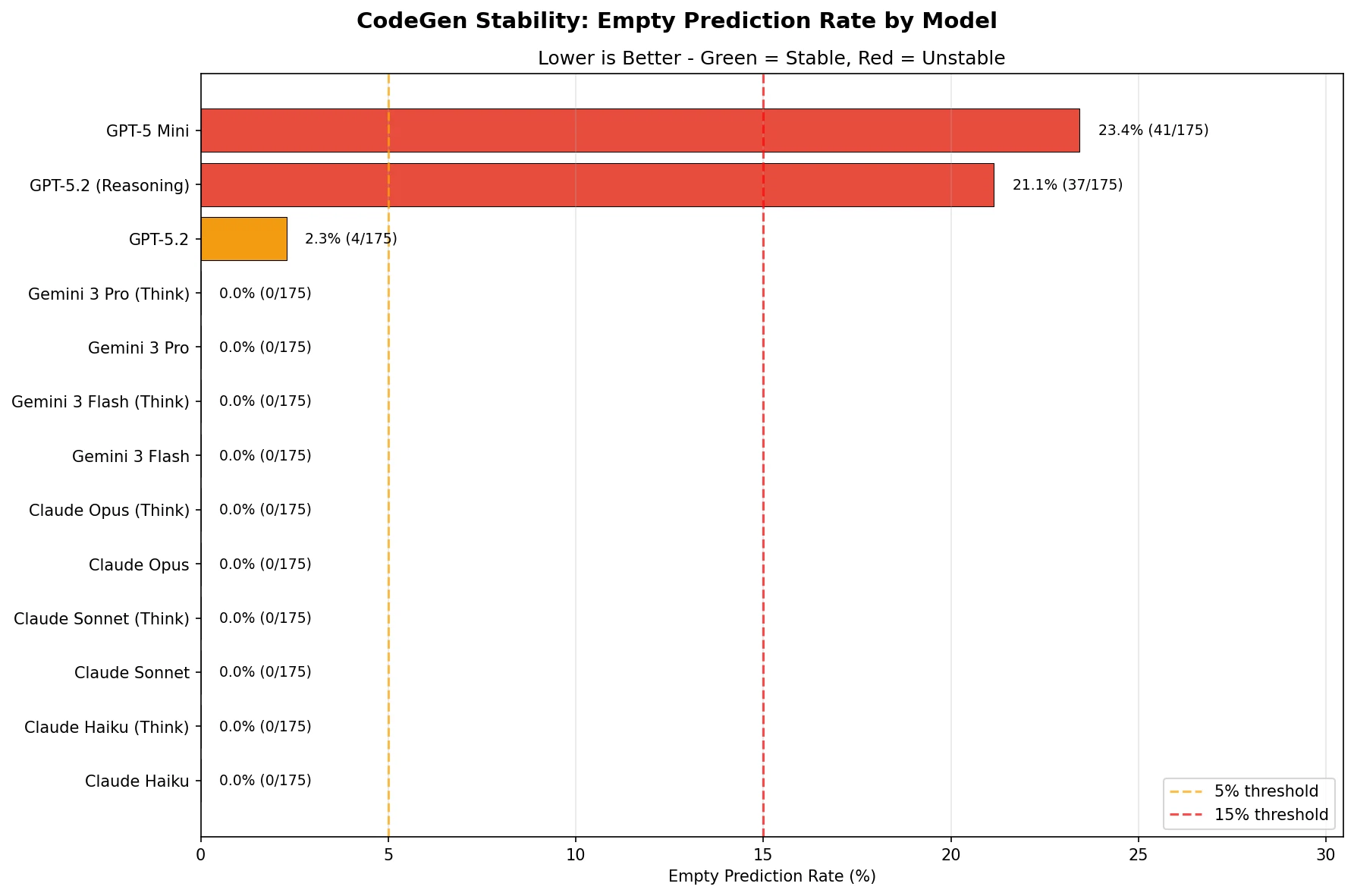
図8:コード生成安定性 — モデル別空応答率
安定性の実質的影響
高い空応答率は以下の問題を引き起こす。
- 実質的品質低下:空応答は0点処理されるため、GPT-5.2(Reasoning)の実質品質は表面的スコアよりもさらに低い。
- リトライコストの増加:空応答発生時にはリトライが必要であり、追加コストと遅延時間を発生させる。
- システム信頼性の低下:20%以上の失敗率はプロダクション環境では許容し難い。
この分析結果から、GPT-5.2(Reasoning)とGPT-5 Miniはコード生成タスクのパイプラインでの使用を推奨しない。
コスト ― 品質分析
モデル別コストおよびコスト効率性
表17は、各モデルの1Kリクエストあたりのコストと品質を整理したものである。
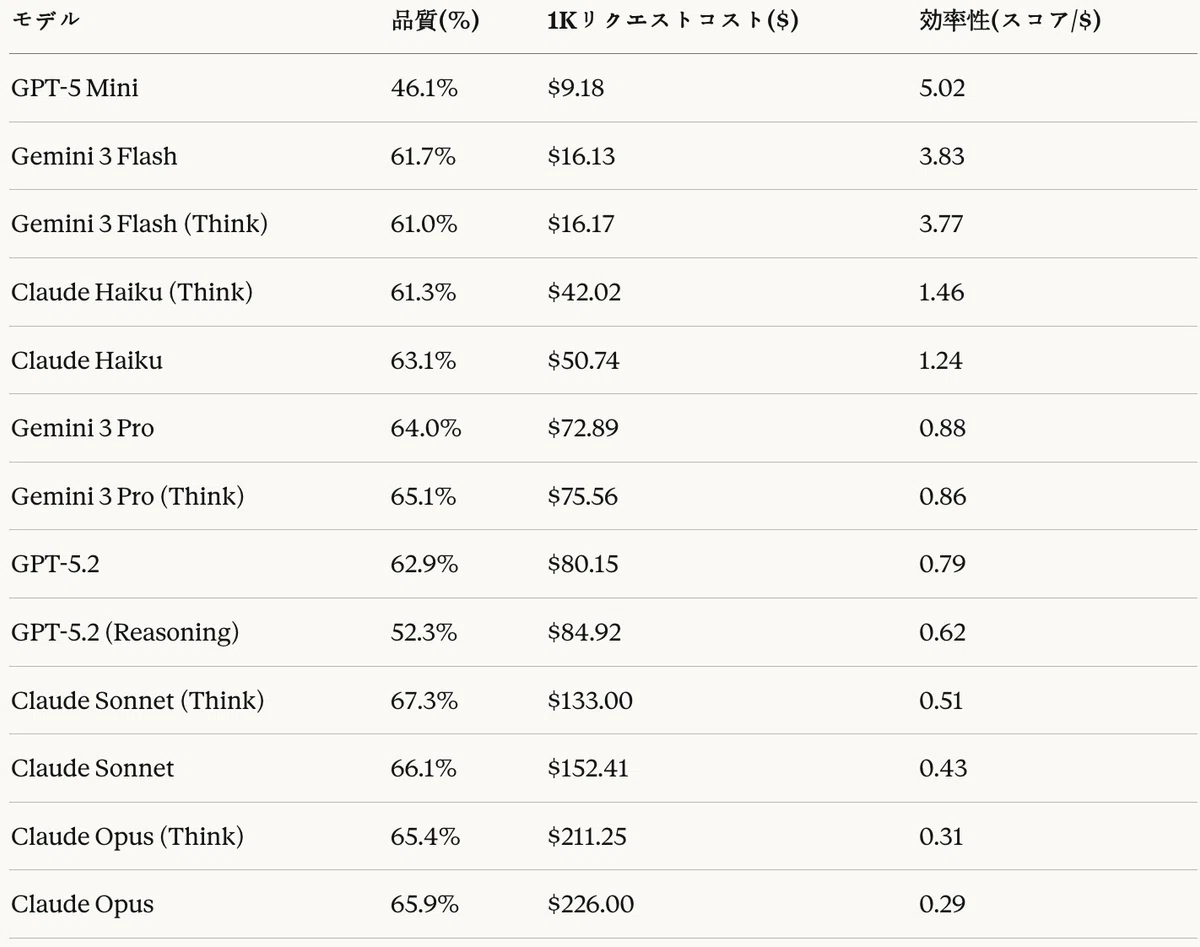
表17:コード生成タスク — コスト分析 — 効率性 = 品質(%)/ コスト($)
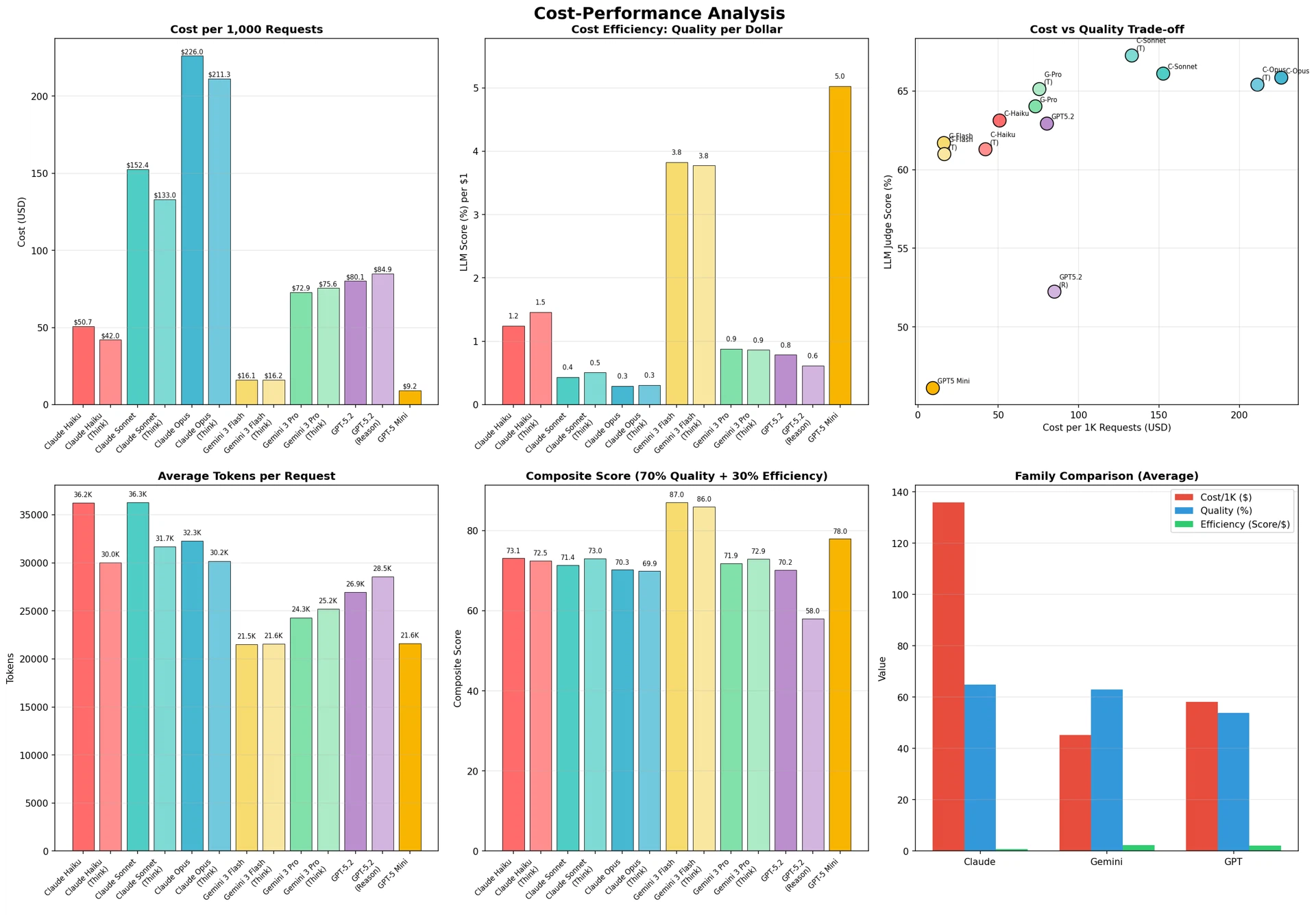
図9:コスト―性能分析
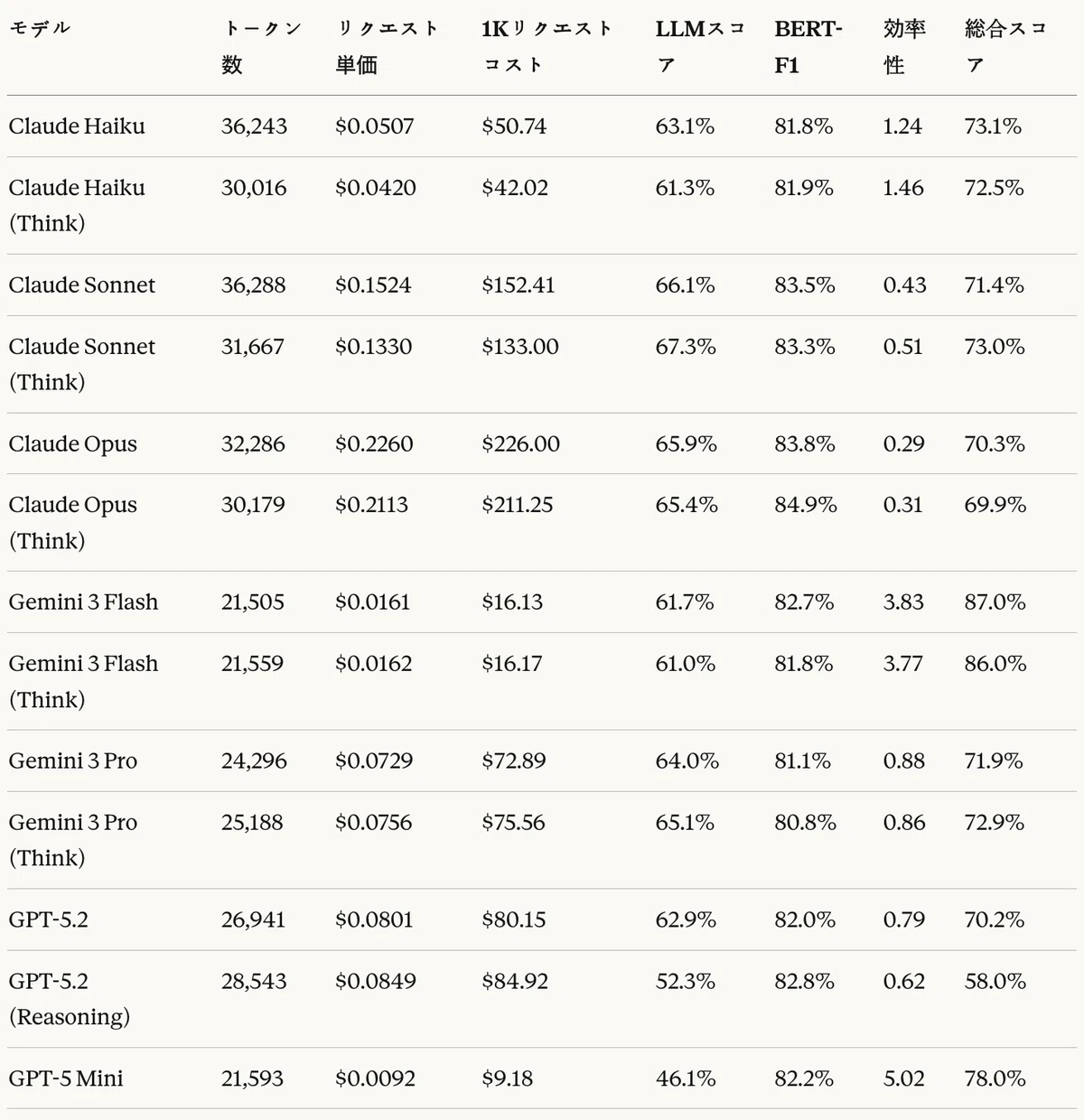
コスト―性能サマリーテーブル
コスト ― 品質トレードオフ
コスト ― 品質分析から、以下のパレート最適構成が導出された。
- 最低コスト最適:Gemini 3 Flash($16.13、61.7%)— コスト対比で最も効率的(3.83点/$)
- バランス最適:Gemini 3 Pro(Think)($75.56、65.1%)— 適切なコストで良好な品質
- 最高品質最適:Claude Sonnet(Think)($133.00、67.3%)— 最高品質が求められる場合
小括
コード生成タスクに対する評価結果を要約すると以下のとおりである。
品質順位(LLM-as-a-Judge基準)
- Claude Sonnet(Think):67.3%
- Claude Sonnet:66.1%
- Claude Opus:65.9%
- Claude Opus(Think):65.4%
- Gemini 3 Pro(Think):65.1%
中核的発見事項
- Claude優位:Claudeモデルが上位を占め、Claude Sonnet(Think)が最高品質を達成した。
- Thinkモードの非対称的効果:ThinkモードはClaude SonnetとGemini 3 Proで肯定的効果(+1.1〜1.2%p)を示したが、Claude Haikuでは否定的(−1.8%p)、GPTでは顕著な否定的効果(−10.6%p)を記録した。
- GPT安定性問題:GPT-5.2(Reasoning)とGPT-5 Miniはそれぞれ21.1%、23.4%の空応答率を記録し、コード生成パイプラインでの使用が不適合である。
- コスト効率性:安定的なモデルの中でGemini 3 Flashが$16.13の低コストで61.7%の品質を提供し、コスト効率性が最も高い(3.83点/$)。

表18:コード生成タスク推奨モデル
次章では、Agentic RAGタスクに対する評価結果を分析し、コード生成タスクとの相違点を比較する。
第5章 実験結果:Agentic RAGタスク
本章では、MFID Mapping AgentのAgentic RAGタスクに対する評価結果を提示する。検索精度と効率性を分析し、Thinkモードの影響およびコード生成タスクとの相違点を検討する。
全体品質評価結果
Recall@KおよびMRR結果
表19は、主要評価指標の結果を整理したものである。
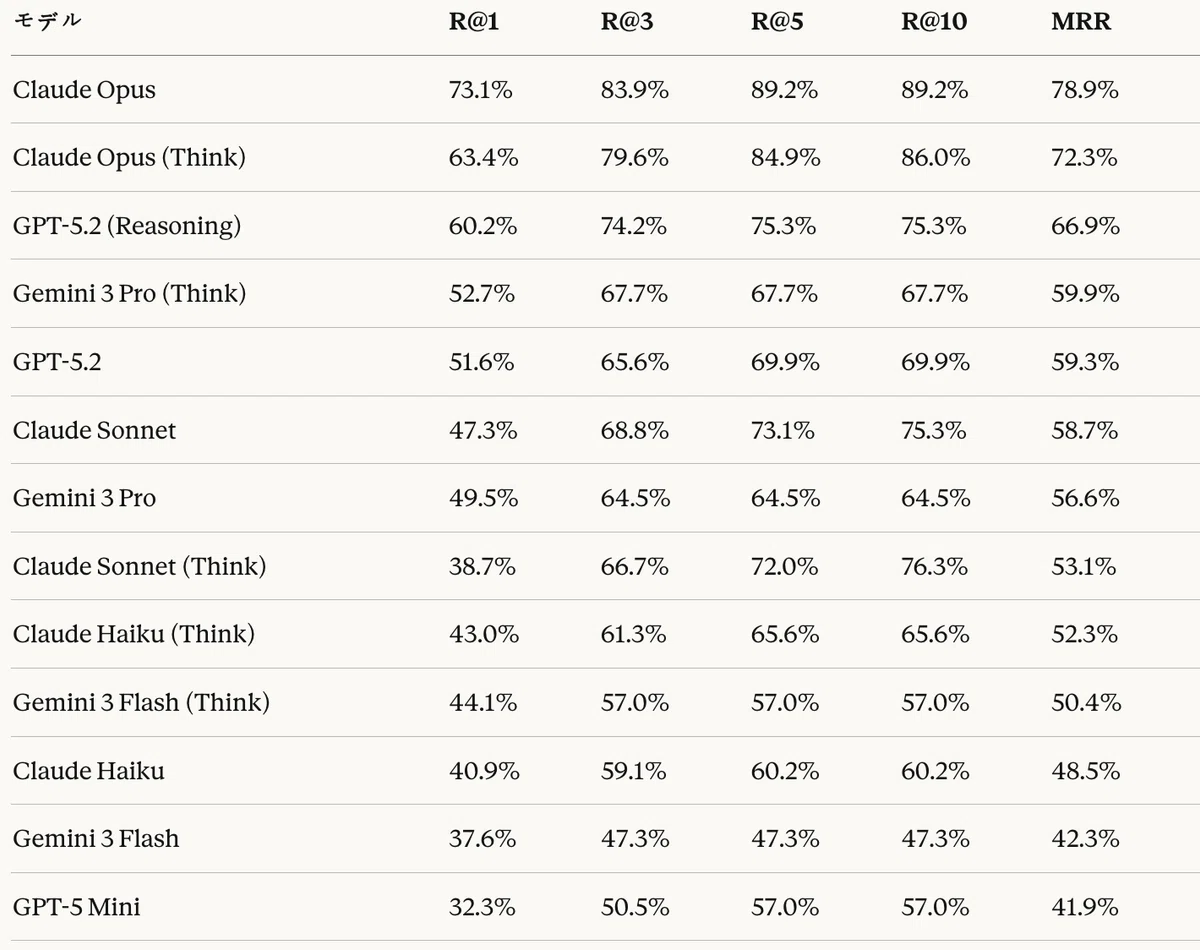
表19:Agentic RAGタスク — 検索性能結果
Agentic RAGタスクにおいて、Claude OpusがMRR 78.9%、R@1 73.1%、R@10 89.2%で1位を記録した。これは2位のClaude Opus(Think)の72.3%より6.6%p高い数値である。
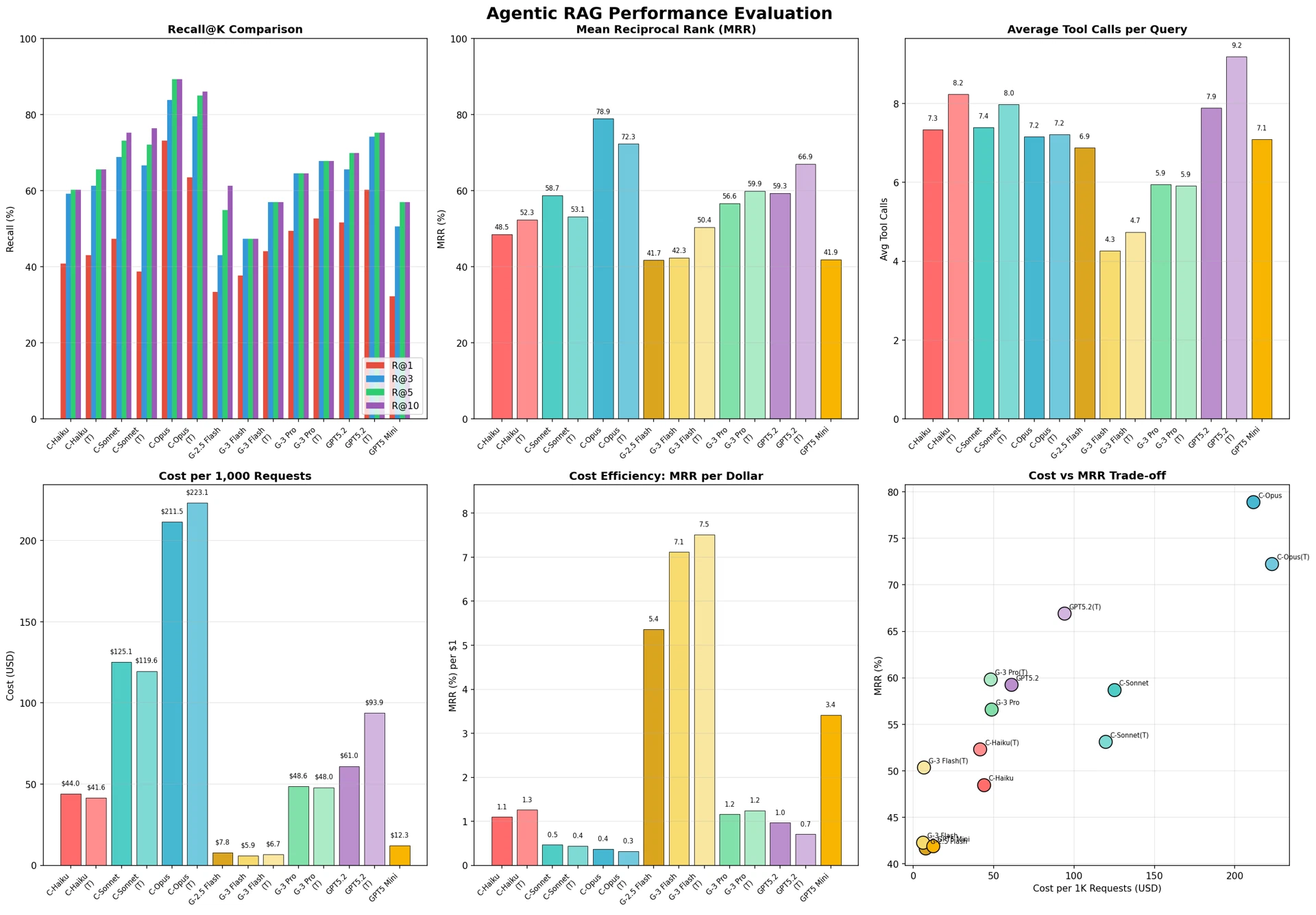
図11:Agentic RAG性能評価
コード生成タスクとは異なり、GPT-5.2(Reasoning) が66.9%で3位を記録した点が注目される。これは、GPTのReasoningモードが複雑な検索およびマッピング推論に効果的であることを示唆している。
ツール呼び出し効率性
表20は、各モデルのクエリあたりの平均ツール呼び出し回数を示す。
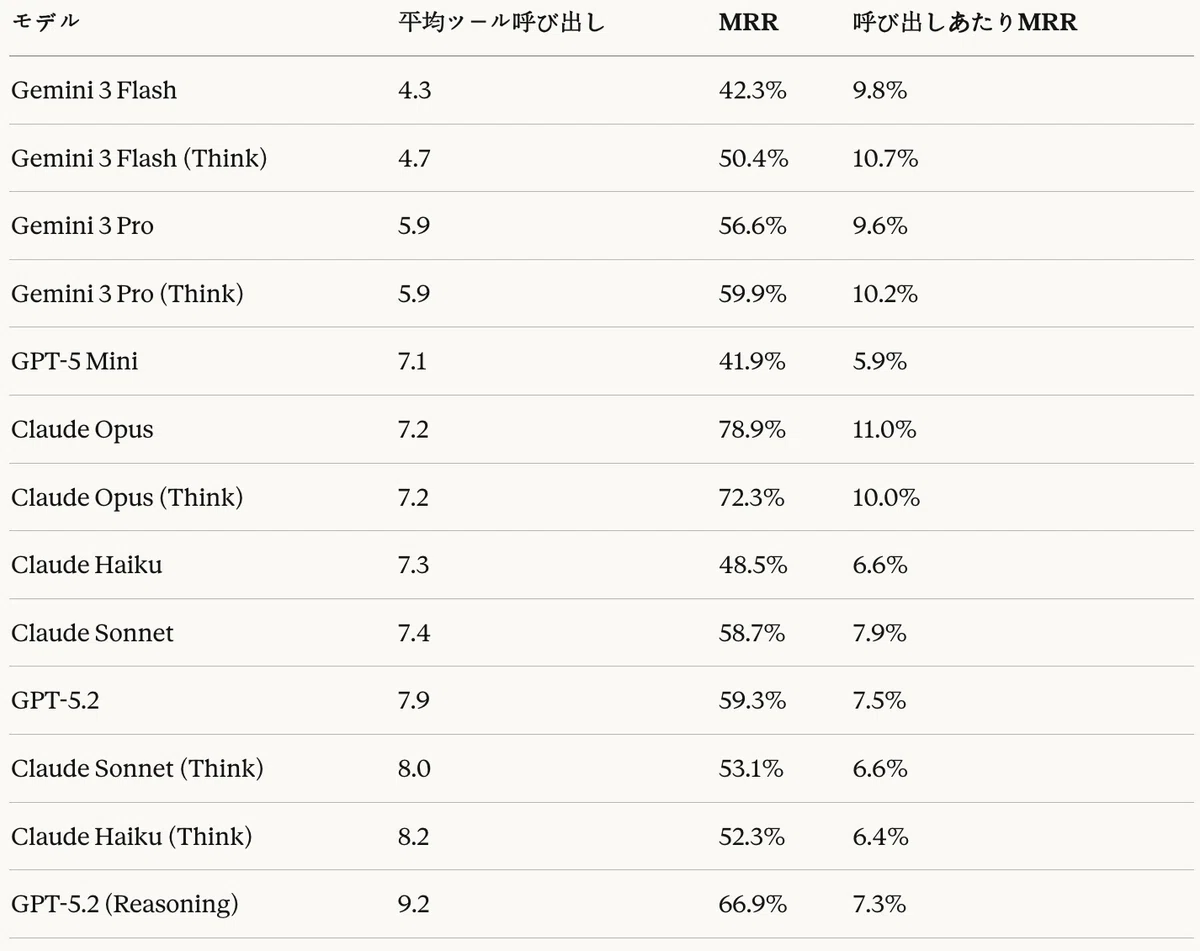
表20:Agentic RAGタスク — ツール呼び出し効率性
Geminiモデルが最も少ないツール呼び出し(4.3〜5.9回)で効率的な検索を実行した。一方、GPT-5.2(Reasoning)は9.2回で最も多くのツール呼び出しを実行したものの、高いMRR(66.9%)を達成した。
呼び出しあたりMRRの観点では、Claude Opus(11.0%)が最も効率的であり、Gemini 3 Flash(Think)(10.7%)がそれに続いた。これは、Claude Opusが適切なツール呼び出し回数(7.2回)で最高の精度を達成していることを意味する。
Agentic RAG評価サマリー
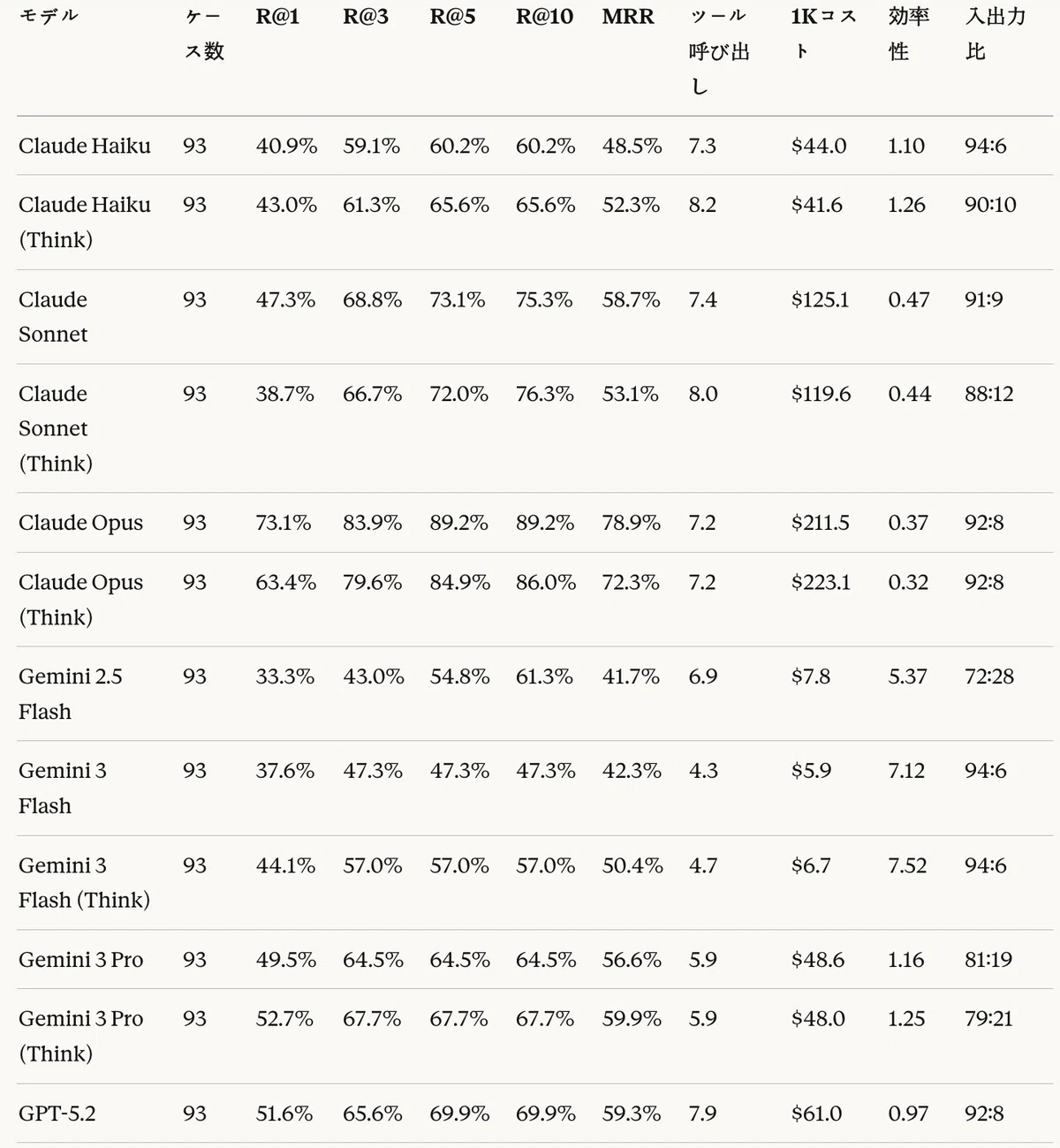
Agentic RAG評価サマリー

Agentic RAG評価サマリー(続き)
Thinkモード効果分析
Thinkモードのタスク別影響
表21は、各モデルにおけるThinkモード有効化に伴うMRRの変化を示す。
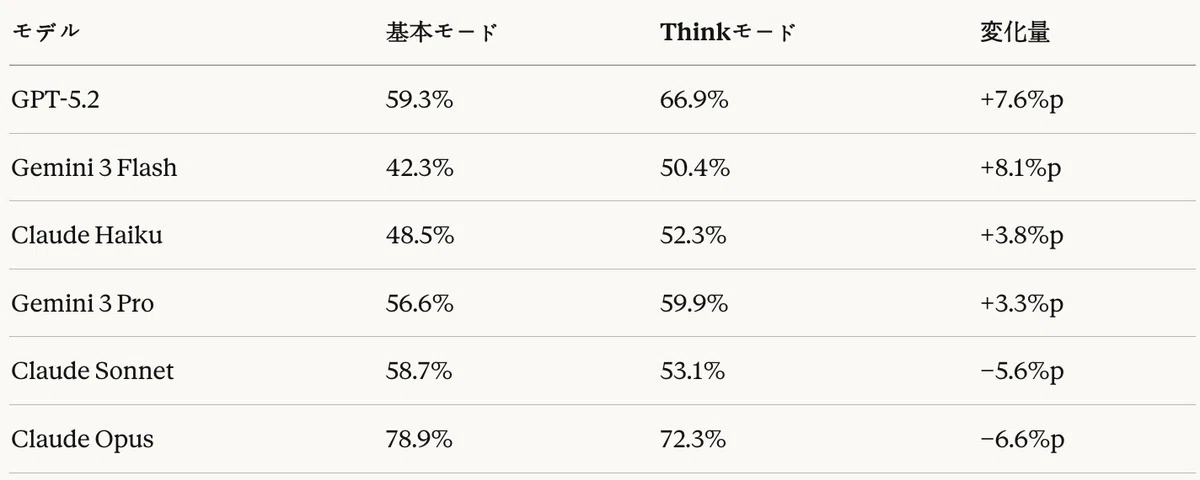
表21:Agentic RAGタスク — Thinkモード効果(MRR基準)
Agentic RAGタスクにおけるThinkモードの効果は、コード生成タスクと正反対のパターンを記録した。
肯定的効果
- Gemini 3 Flash:+8.1%p(最大の向上)
- GPT-5.2:+7.6%p(コード生成では−10.6%pであった)
- Claude Haiku:+3.8%p
- Gemini 3 Pro:+3.3%p
否定的効果
- Claude Opus:−6.6%p(基本モードが既に最高性能)
- Claude Sonnet:−5.6%p
タスク別Thinkモード効果比較
表22は、コード生成とAgentic RAGタスクにおけるThinkモード効果を比較したものである。
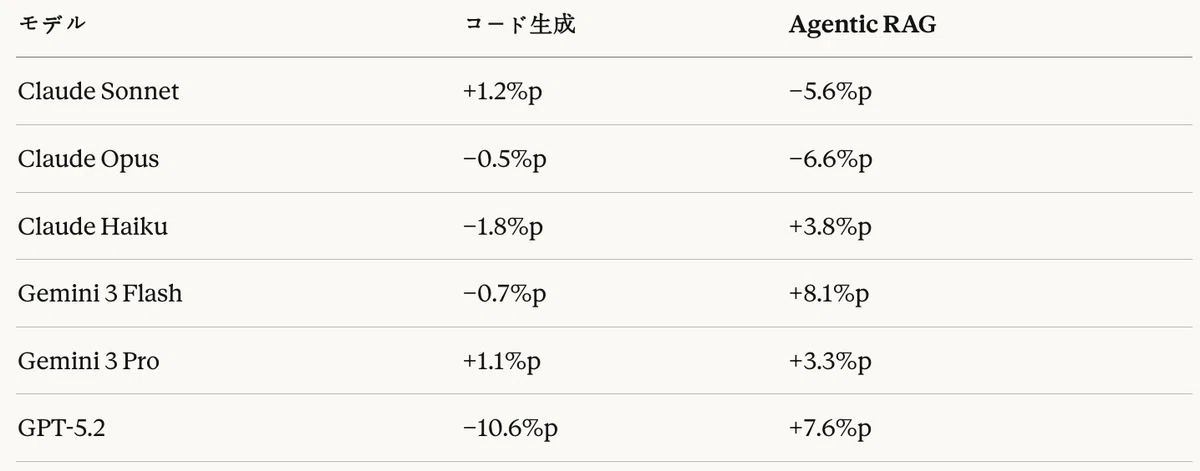
表22:タスク別Thinkモード効果比較
分析の結果、GPT-5.2の完全に正反対のパターンが際立っている。
- コード生成:−10.6%p(顕著な低下)
- Agentic RAG:+7.6%p(有意な向上)
この結果は、GPTのReasoningモードが定型化されたコード生成よりも、複雑な検索および推論タスクに適合するよう設計されていることを示唆している。
コスト ― 品質分析
モデル別コストおよびコスト効率性
表23は、各モデルの1Kリクエストあたりのコストとコスト効率性を整理したものである。
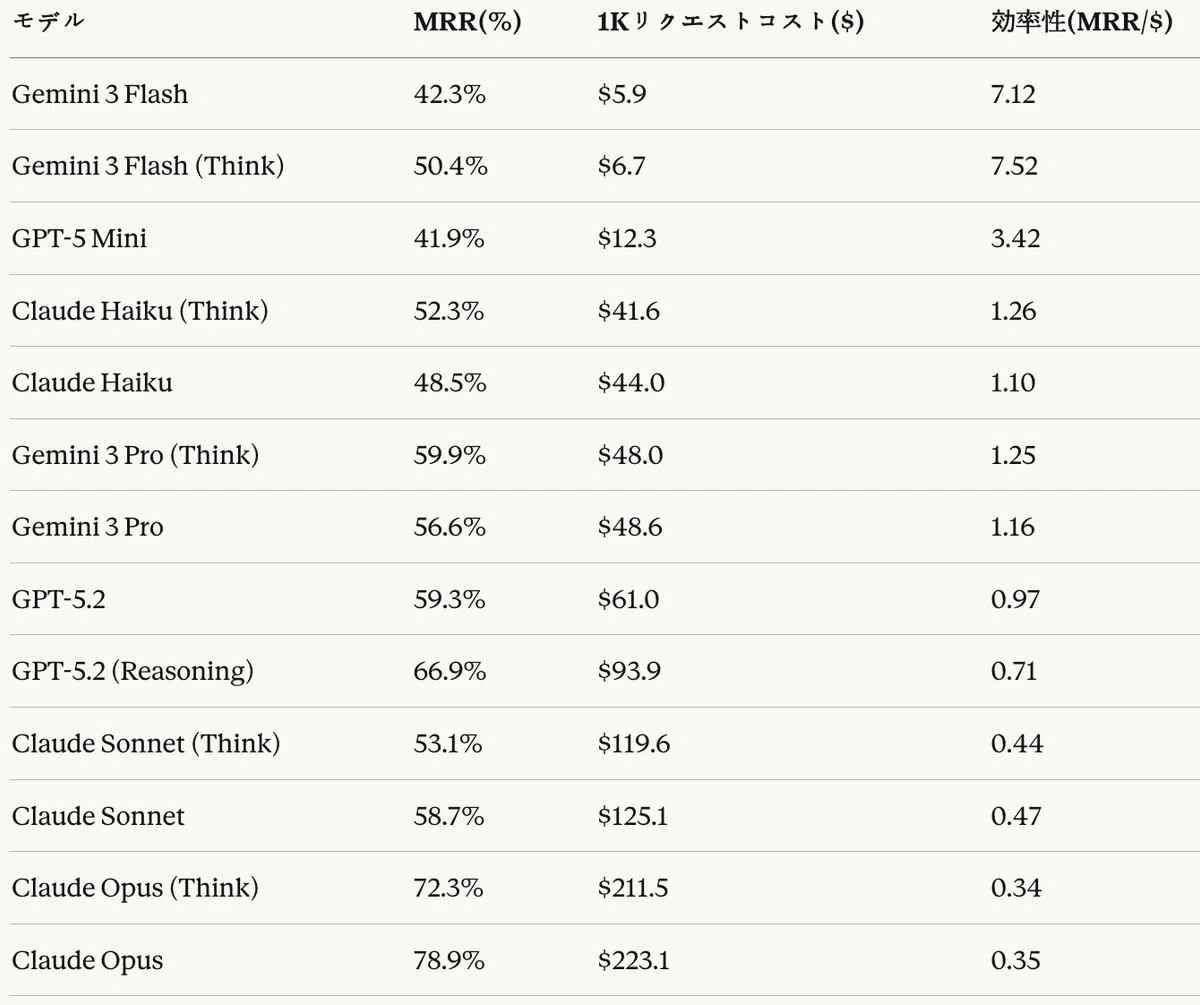
表23:Agentic RAGタスク — コスト分析 — 効率性 = MRR(%)/ コスト($)
コスト ― 品質トレードオフ
コスト ― 品質分析から、以下のパレート最適構成が導出された。
- 最低コスト最適:Gemini 3 Flash(Think)($6.7、50.4%)— 最も高いコスト効率性(7.52 MRR/$)
- バランス最適:Gemini 3 Pro(Think)($48.0、59.9%)— 適切なコストで良好な品質
- 最高品質最適:Claude Opus($223.1、78.9%)— 最高MRRが求められる場合
コード生成タスクと比較すると、Agentic RAGではGemini 3 Flash(Think) が基本モードより効率的であり、Claude Opus基本モードがThinkモードより優れているという点が異なる。
コード生成 vs Agentic RAG比較
モデル順位の変化
表24は、2つのタスクにおけるモデル順位を比較したものである。
表24:タスク別モデル順位比較(上位5位)
主な変化:
- Claude Opus:コード生成3位 → Agentic RAG 1位
- GPT-5.2(Reasoning):コード生成12位 → Agentic RAG 3位(9段階上昇)
- Claude Sonnet(Think):コード生成1位 → Agentic RAG 8位
タスク特性に応じたモデル適合性
2つのタスクの結果を総合すると、以下のパターンが導出される。
コード生成に強いモデル
- Claude Sonnet(Think):構造化された出力生成に強み
- Claude Sonnet:安定したコード品質
Agentic RAGに強いモデル
- Claude Opus:複雑なドメイン推論に強み
- GPT-5.2(Reasoning):多段階検索推論に効果的
両タスクでバランスの取れたモデル
- Gemini 3 Pro(Think):両タスクともに上位圏
- GPT-5.2:両タスクともに中上位圏
小括
Agentic RAGタスクに対する評価結果を要約すると以下のとおりである。
品質順位(MRR基準)
- Claude Opus:78.9%
- Claude Opus(Think):72.3%
- GPT-5.2(Reasoning):66.9%
- Gemini 3 Pro(Think):59.9%
- GPT-5.2:59.3%
中核的発見事項
- Claude Opus優位:Claude OpusがMRR 78.9%で1位を記録し、これは2位より6.6%p高い。
- GPT Reasoningの逆転:コード生成で最下位圏であったGPT-5.2(Reasoning)がAgentic RAGでは3位を記録し、タスク別適合性の差異を示した。
- Thinkモードの反対効果:コード生成とは異なり、Agentic RAGではGPTとGeminiのThinkモードが肯定的効果を示し、Claudeの上位モデル(Opus、Sonnet)はむしろ否定的効果を記録した。
- コスト効率性:Gemini 3 Flash(Think)が$6.7の低コストで50.4%のMRRを提供し、コスト効率性が最も高い(7.52 MRR/$)。

表25:Agentic RAGタスク推奨モデル
次章では、2つのタスクの結果を総合し、パイプライン最適化戦略と最終的な推奨事項を提示する。
第6章 総合分析および推奨事項
本章では、コード生成とAgentic RAGの2つのタスクの結果を総合し、パイプライン最適化戦略を提示する。モデル別の特性を要約し、コスト―品質トレードオフを考慮した最終的な推奨事項を導出する。
パイプライン総合分析
段階別性能比較
表26は、各モデルの2タスクにおける性能と総合品質を整理したものである。
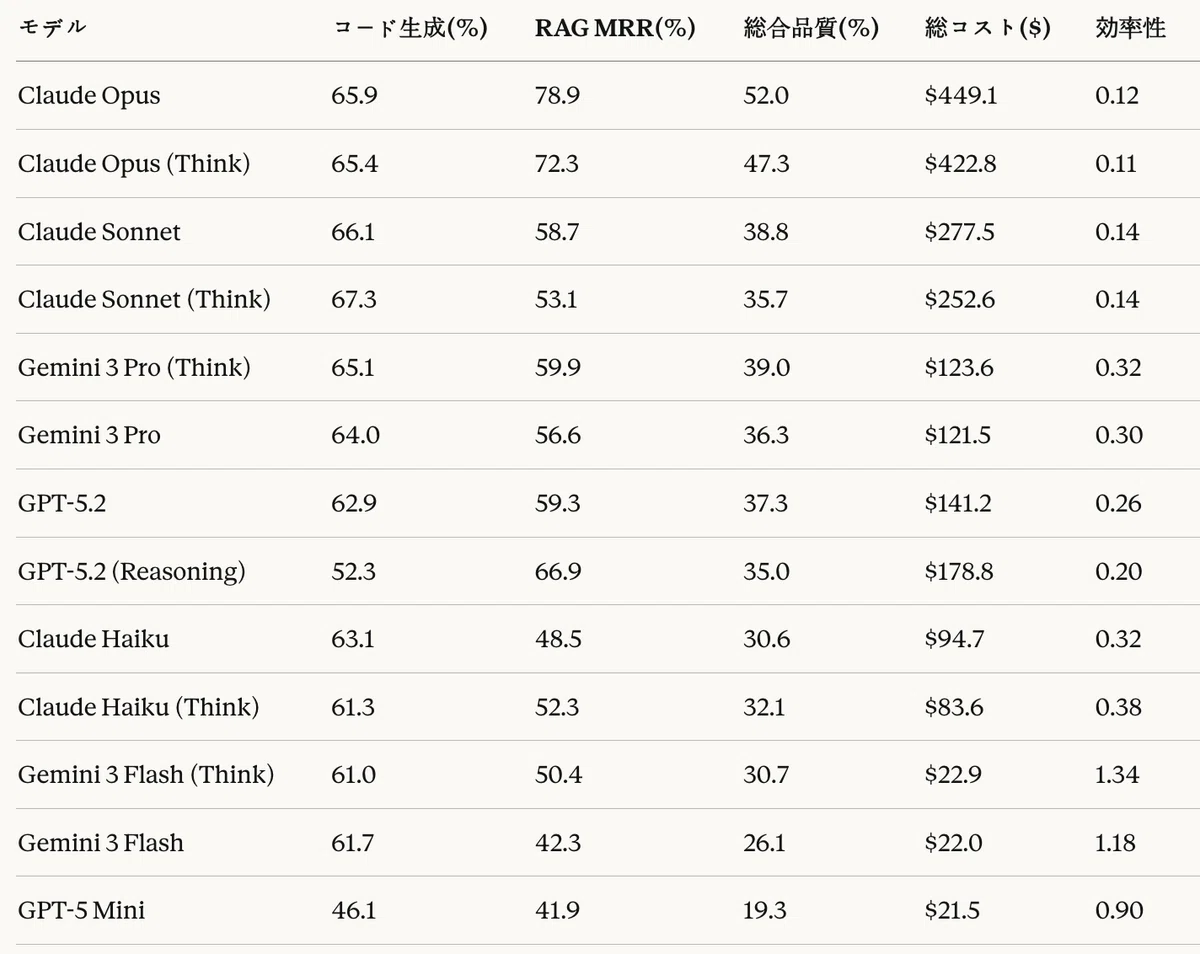
表26:パイプライン総合性能分析
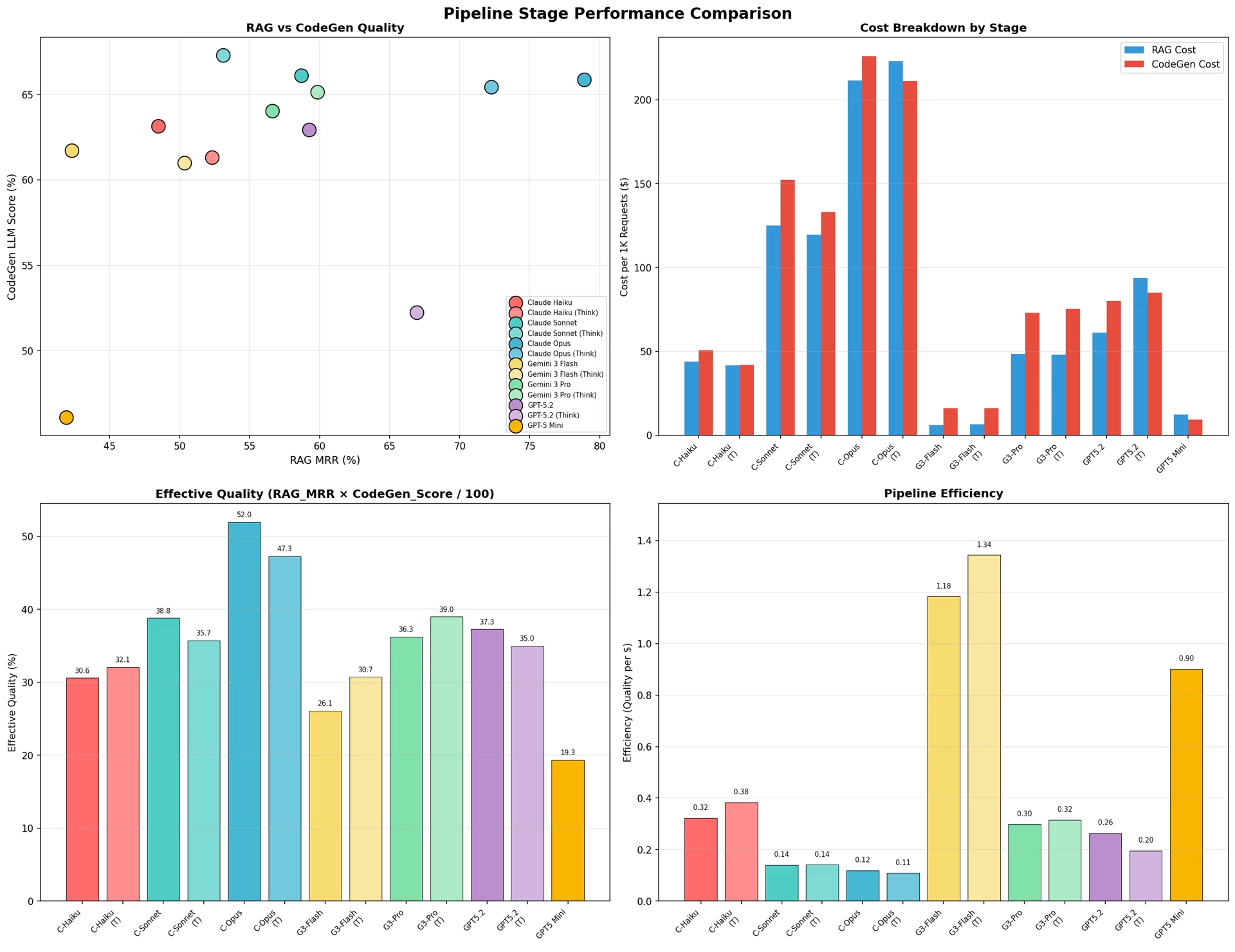
図13:パイプライン段階別性能比較
効果的品質分析
総合品質の観点では、Claude Opusが52.0%で最も高く、これはコード生成(65.9%)とRAG(78.9%)の両方で優れた性能を示したためである。総コスト($449.1)が最も高いため、効率性(0.12)は低かった。
コスト効率性の観点では、Gemini 3 Flash(Think) が1.34で最も高かった。これは低コスト($22.9)で良好な総合品質(30.7%)を達成したためである。
モデル別特性の要約
個別モデル特性
Claude Opus
- コード生成:3位(65.9%)
- Agentic RAG:1位(78.9%)
- 特徴:両タスクともに最上位圏、複雑なドメイン推論に強み
- 推奨:最高品質が求められる場合
Claude Sonnet(Think)
- コード生成:1位(67.3%)
- Agentic RAG:8位(53.1%)
- 特徴:コード生成特化、Thinkモードが効果的
- 推奨:コード生成品質が重要な場合
Gemini 3 Flash(Think)
- コード生成:11位(61.0%)
- Agentic RAG:10位(50.4%)
- 特徴:最低コスト、最も高い効率性
- 推奨:予算制約が厳しい場合
GPT-5.2(Reasoning)
- コード生成:12位(52.3%)
- Agentic RAG:3位(66.9%)
- 特徴:タスク別の性能差が極端、コード生成は不安定
- 推奨:RAGタスク単独使用のみ推奨
Thinkモード効果の総合
タスク別Thinkモード影響
表27は、Thinkモードのタスク別効果を総合したものである。
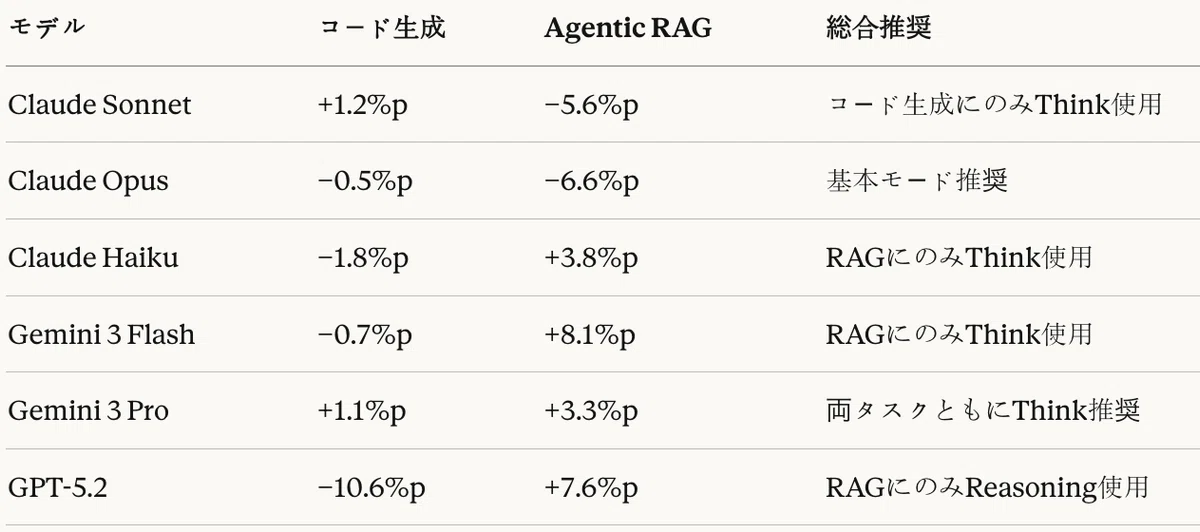
表27:Thinkモード効果総合
Thinkモード戦略
Thinkモードの効果がタスクによって異なるため、異種モデルパイプライン(Heterogeneous Pipeline)戦略が効果的である。
- コード生成段階:Claude Sonnet(Think)またはGemini 3 Pro(Think)
- Agentic RAG段階:Claude Opus(基本)またはGemini 3 Flash(Think)
この戦略は、各段階において最適な性能達成を可能にする。
パイプライン最適化戦略
パイプライン組み合わせ分析
AI Checkシステムはコード生成とAgentic RAGを逐次的に実行するため、各段階に異なるモデルの適用が可能である。13モデル × 13モデル = 169の組み合わせの中からパレート最適な組み合わせを導出した。
推奨パイプライン構成
表28は、シナリオ別の推奨パイプライン構成を示す。

表28:シナリオ別推奨パイプライン構成 — 現行構成(Claude Sonnet + Claude Sonnet):品質 約62%、コスト 約$277
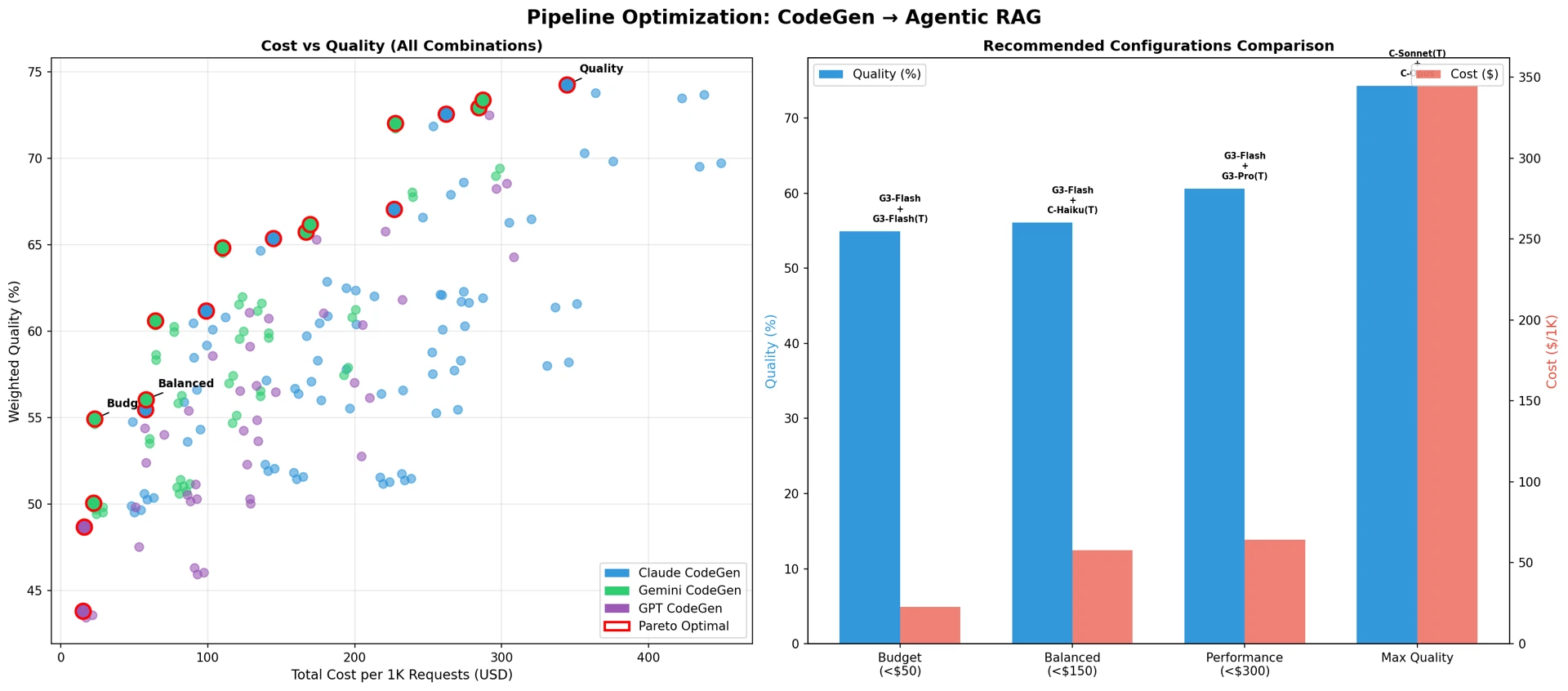
図14:パイプライン最適化:CodeGen → Agentic RAG
最適化効果
現行のClaude Sonnet単一モデル使用に対する推奨構成の改善効果:
予算構成(Gemini 3 Flash + Gemini 3 Flash(Think))
- コスト:$277 → $23(92%削減)
- 品質:62% → 54%(8%p減少)
- コスト効率性:10倍向上
バランス構成(Gemini 3 Flash + Claude Haiku(Think))
- コスト:$277 → $58(79%削減)
- 品質:62% → 65%(3%p向上)
- コスト効率性:5倍向上
最高品質構成(Claude Sonnet(Think)+ Claude Opus)
- コスト:$277 → $356(29%増加)
- 品質:62% → 74%(12%p向上)
- 品質あたりコスト:改善
最終推奨事項
研究課題に対する回答
RQ1:ドメイン特化タスクにおけるLLMモデル間の性能差異はどのようなものか?
モデル間の性能差異は有意であり、タスク類型に応じて最適モデルが異なる。
- コード生成:Claude Sonnet(Think)> Claude Sonnet > Claude Opus
- Agentic RAG:Claude Opus > Claude Opus(Think)> GPT-5.2(Reasoning)
RQ2:Think/Reasoningモードはタスク別にどのような影響を及ぼすか?
Thinkモードの効果はタスクによって異なり、一部のモデルでは正反対のパターンを示す。
- GPT-5.2:コード生成 −10.6%p、Agentic RAG +7.6%p
- Claude Opus:両タスクともに基本モードが優秀
RQ3:コスト―品質トレードオフにおける最適構成は何か?
異種モデルパイプラインが同種モデルパイプラインより効率的である。
- バランス構成:Gemini 3 Flash(コード生成)+ Claude Haiku(Think)(RAG)
- 79%のコスト削減と3%pの品質向上を同時に達成
RQ4:プロダクション環境で考慮すべき要素は何か?
安定性が重要な要素であり、GPTモデルの高い空応答率(21〜23%)はプロダクション使用に不適合である。ClaudeとGeminiモデルは0%の空応答率で安定的である。
実務適用ガイドライン
単一モデル使用時

単一モデル使用時ガイドライン
異種モデルパイプライン使用時
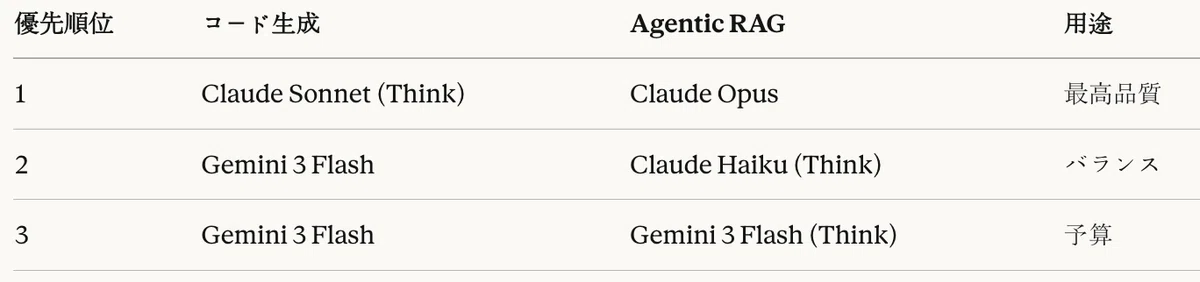
異種モデルパイプライン使用時ガイドライン
小括
本章では、コード生成とAgentic RAGの2つのタスクの結果を総合し、以下の結論を導出した。
- 異種モデルパイプラインの効果性:各タスクに最適化されたモデルの組み合わせにより、コスト削減と品質向上を同時に達成できることが確認された。
- Thinkモードの選択的適用:Thinkモードは普遍的な効果を保証しないため、タスクとモデルの特性を考慮した選択的適用が求められる。
- 安定性の重要性:品質のほかに空応答率などの安定性指標も、プロダクションモデル選択における中核的な考慮要素として作用する。
- コスト効率性:Geminiモデルがコスト効率性の面で優位を示し、予算制約のある環境において有効な選択肢となる。
結論
研究の要約
本研究は、日本の給与システムAI Checkを対象として、3大LLMプロバイダー(Anthropic、Google、OpenAI)の13のモデル構成に対する比較評価を実施した。自然言語―CTE擬似コード変換(コード生成、175サンプル)とドメイン用語―MFIDマッピング(Agentic RAG、93サンプル)タスクに対して品質、コスト、安定性を分析した。
コード生成タスクではClaude Sonnet(Think)が67.3%で最高性能を記録し、Agentic RAGタスクではClaude Opusが78.9%のMRRで1位を記録した。Think/Reasoningモードの効果はタスク類型に応じて異なる結果を示し、GPT-5.2はコード生成で−10.6%p、Agentic RAGで+7.6%pと相反するパターンを記録した。
コスト―品質分析の結果、異種モデルパイプライン(Heterogeneous Pipeline)が同種モデルパイプラインより効率的であることが確認された。Gemini 3 Flash(コード生成)とClaude Haiku(Think)(Agentic RAG)の組み合わせによるバランス構成は、Claude Sonnet単一モデルに対して79%のコスト削減と3%pの品質向上を達成した。
主要な貢献
本研究の貢献は以下のとおり整理される。
第一に、実際の企業環境に基づくLLM比較評価を実施した。汎用ベンチマークに依拠した既存研究とは異なり、本研究は運用中の日本の給与システムのパイプラインを対象として13のLLM構成に対する評価を行い、ドメイン特化タスクにおけるモデル性能を実証的に比較した。
第二に、コード生成とAgentic RAGという異なるタスク類型におけるモデル特性を解明した。同一モデルであってもタスク類型に応じて性能順位が大幅に変動し得ることを実証し、Think/Reasoningモードの効果がタスクによって正反対に現れ得ることを確認した。
第三に、多次元評価フレームワークを提案した。伝統的テキスト指標(BLEU、ROUGE-L、BERT-F1)とLLM-as-a-Judgeベースの4次元評価(構文正確性、意味等価性、条件完全性、構造的類似性)を組み合わせ、コード生成品質を多角的に測定した。Agentic RAGに対してはRecall@K、MRRとツール呼び出し効率性を評価した。
第四に、コスト―品質トレードオフに基づくパイプライン最適化戦略を提示した。169のパイプラインの組み合わせを分析してシナリオ別の最適構成を導出し、異種モデルパイプラインの効果性を実証した。
実務的示唆
本研究の結果は、LLMベースのエンタープライズシステム開発の実務者に対して以下の示唆を提供する。
モデル選択のタスク依存性:単一モデルがすべてのタスクで最適であるという仮定は根拠に乏しい。タスク別に最適モデルが異なり得るため、パイプラインの各段階に対する個別のモデル評価が求められる。
Thinkモードの選択的適用:Think/Reasoningモードが性能を普遍的に向上させると断定することはできない。一部のモデル―タスクの組み合わせでは性能低下が観察されるため、事前検証が不可欠である。
安定性評価の重要性:品質指標のみに依拠したモデル選択はプロダクション環境で問題を引き起こし得る。GPTモデルの高い空応答率(21〜23%)は、品質スコアとは無関係にプロダクション使用を制限する要因として作用する。
コスト効率性の考慮:最高品質モデルが常に最善の選択とは限らない。Gemini 3 Flashのような低コストモデルが十分な品質を提供しつつ、10倍以上のコスト効率性を達成し得る。
研究の限界
本研究は以下の限界を内包する。
第一に、単一ドメイン評価である。日本の給与システムという特定ドメインに限定された評価であり、他ドメインや言語への一般化には追加検証が求められる。
第二に、静的評価データセットである。175件のコード生成サンプルと93件のRAGサンプルは、実際のシステムのシナリオを網羅できていない可能性がある。複雑度やエッジケースを含む拡張データセットの構築が求められる。
第三に、単一時点の評価である。LLMが継続的にアップデートされることを考慮すると、本研究の結果は評価時点のモデルバージョンに限定される。モデルバージョン変更に伴う性能変化を追跡する継続的評価体制が必要である。
第四に、単一ターン評価である。本研究は各サンプルに対する単一ターンの応答のみを評価しており、マルチターンの相互作用やエラー復旧能力は評価範囲から除外されている。
今後の研究方向
本研究を基盤として、以下の後続研究が考えられる。
多ドメイン拡張:給与システムのほかに会計、人事、物流などの企業ドメインへ評価を拡張し、モデル特性の一般化可能性を検証する必要がある。
動的モデル選択:入力の複雑度や類型に応じてリアルタイムで最適モデルを選択するルーティングメカニズムの開発により、コストと品質の動的最適化が可能になると見込まれる。
マルチターンエージェント評価:単一ターン応答ではなくマルチターン対話におけるエージェント性能を評価し、エラー復旧、明確化質問、段階的改善能力などを含むエージェント評価フレームワークの開発が求められる。
継続的評価パイプライン:モデルバージョンアップデートに伴う性能変化を自動的に追跡するCI/CDベースの評価パイプラインの構築により、モデルアップデート時点での迅速な再評価と意思決定が可能になるであろう。
コスト予測モデル:入力特性(長さ、複雑度、ドメイン)に基づいて各モデルのコストと品質を予測するモデルの開発により、リクエストレベルでの最適モデル選択が実現され得る。
結び
本研究は、LLMベースのエンタープライズシステム開発において、体系的なモデル評価と選択の重要性を提示するものである。単一ベンチマークやプロバイダーの公式性能指標のみでは、実際のドメインタスクにおける性能を予測することは困難であり、タスク別、モード別に異なるモデル特性を考慮したカスタマイズ評価が不可欠である。
多段階パイプラインを有するシステムでは、異種モデルの組み合わせによりコスト効率性と品質を同時に改善することが可能である。本研究で提案した評価フレームワークと最適化戦略が、LLMベースの企業システム開発における参考資料として貢献することを期待する。
📖 本記事の研究背景・システムアーキテクチャ・実験設計については前編をご参照ください。
🚀 QueryPie AIを今すぐ体験する