コード生成およびAgentic RAGタスクを中心とした特定ドメインのためのLLM比較評価【前編】


📖 読了時間:約20分
本記事は前後編の前編です。前編では研究の背景・システムアーキテクチャ・実験設計を、後編では実験結果・パイプライン最適化・結論を取り扱います。
序論
研究の背景と動機
大規模言語モデル(LLM)の飛躍的な発展は、企業向けアプリケーション設計のパラダイムに根本的な再考を迫っている。とりわけ自然言語処理とコード生成、情報検索技術の融合は、給与および人事管理のように定められたルールを厳格に遵守すべきエンタープライズ領域にまで自動化の可能性を拡張させた。
このうち給与システムは、複雑な法規と税金計算、多層的な社会保険料算定基準が絡み合い、高度な正確性が求められるドメインである。特に日本の給与体系は、雇用保険、健康保険、厚生年金などの複合的な社会保険制度と、年末調整および住民税特別徴収の手続きが混在しており、実務者が自然言語で記述された業務ルールをシステムロジックへ変換する過程において、相当な人的資源と時間を費やすことになる。
本研究が分析対象とした「AI Check」は、こうしたボトルネックを解消するために3段階パイプライン(Three-stage pipeline)構造を採用した。第1段階では自然言語ベースの給与検査観点(perspective)をSQL形式の擬似コード(pseudocode)に変換し、第2段階では擬似コード内のドメイン用語をデータベースフィールド識別子(MFID)にマッピングし、第3段階ではMFIDがマッピングされた擬似コードを実行可能なSQLクエリに変換する。この過程でLLMは単なるテキスト生成を超え、コード生成(Code Generation)と検索拡張生成(RAG)ベースのエージェント的(Agentic)タスクを遂行することになる。
現在、AnthropicのClaude、GoogleのGemini、OpenAIのGPTなど主要ベンダーは、推論能力を強化した「Thinking」あるいは「Reasoning」モードを競争的に導入している。しかし、実際の企業環境、とりわけ前述の多段階パイプライン内においてこれらの高性能モードがタスクごとの適合性を有するか、そしてコスト対比で実質的な性能向上に寄与するかに関する実証的な比較研究は、依然として空白のまま残されている。
パイプラインの各段階は異なる能力を要求する。コード生成段階が構文の正確性と論理的完結性を最優先とするならば、Agentic RAG段階はツール選択の適切性と検索結果の解釈能力が核心となる。加えてプロダクション環境では、単なる品質スコアを超えてコスト効率性と応答の安定性(空応答およびエラー制御)がシステムの成否を分ける決定的な変数として作用する。
そこで本研究は、日本の給与システムの実際のパイプラインをテストベッドとし、主要LLMのモデル構成に応じた性能差異を定量的に分析することを目的とする。さらに各タスクの特性に最適化されたモデルを特定することで、品質とコスト効率性を同時に達成し得るパイプライン構成戦略を提言することに主眼を置く。
研究課題
本研究は、以下の研究課題に答えることを目指す。
RQ1. コード生成とAgentic RAGタスクにおけるLLMモデルファミリー別の性能差異はどのようなものか?
Claude、Gemini、GPTの3つのモデルファミリーが、自然言語―擬似コード変換(コード生成)と用語―MFIDマッピング(Agentic RAG)タスクにおいて示す性能差異を分析する。BLEU、ROUGE-L、BERT-F1などの伝統的指標とLLM-as-a-Judgeベースの評価、さらにRecall@K、MRRなどの検索指標を活用し、多角的に比較する。
RQ2. Thinking/Reasoningモードが各タスクの性能に及ぼす影響は何か?
各プロバイダーが提供する拡張推論モード(ClaudeのExtended Thinking、GeminiのThinking、GPTのReasoning)が、コード生成とAgentic RAGタスクにおいて実際に性能向上をもたらすのか、あるいはむしろ性能低下を招くのかをタスク別に分析する。
RQ3. モデル別の安定性(空応答率)はどのように異なり、それがモデル選択にどのような影響を及ぼすか?
LLMの実際の運用環境において、空応答(empty response)やエラーの発生頻度はシステムの信頼性に直接的な影響を及ぼす。各モデルの空応答率を測定し、品質スコアと併せて考慮した場合に、実質的なモデル選択基準がどのように変化するかを分析する。
RQ4. コスト―品質トレードオフを考慮した最適なパイプライン構成は何か?
単一モデルをパイプライン全体に使用する場合と、各段階に異なるモデルを使用する混合構成のコスト―品質トレードオフを分析する。予算制約と品質要件に応じた最適なモデルの組み合わせを導出し、パレート最適(Pareto-optimal)構成を特定する。
研究の貢献
本研究の主要な貢献は以下のとおり整理される。
第一に、実際の企業環境に基づくLLM比較評価を実施した。汎用ベンチマークデータセットに依拠した既存研究とは異なり、本研究は実際に運用中の日本の給与システムのパイプラインを対象として、13のLLM構成(Claude 6種、Gemini 4種、GPT 3種)に対する体系的な評価を行うことで、ドメイン特化タスクにおけるモデル性能を実証的に比較した。
第二に、Thinking/Reasoningモードのタスク依存的効果を解明した。分析の結果、Thinkingモードは普遍的な性能向上を保証するものではなく、タスクとモデルに応じて相反する効果を示した。Claudeモデルはコード生成においてThinkingモード適用時に+1.2%pの向上を見せた一方、Agentic RAGでは-6.6%pの性能低下を記録し、GPTモデルはこれと正反対のパターンを記録した。この結果は、Thinkingモードの無分別な適用が逆効果を招き得ることを示唆している。
第三に、品質指標を超えた安定性評価フレームワークを提示した。品質指標に偏重した既存のLLM評価研究とは異なり、本研究は空応答率(empty response rate)を中核的な評価基準として組み込んだ。GPTモデルのReasoning変形はコード生成タスクにおいて21〜23%の空応答率を記録し、競争力のある品質スコアにもかかわらずプロダクション環境への適用が不適切であることを確認した。これはLLM評価における安定性指標の重要性を浮き彫りにしている。
第四に、60%のコスト削減を可能にする最適化パイプライン構成を提案した。単一モデルをパイプライン全体に使用する従来の方式に対し、各段階の特性に適合するモデルを戦略的に組み合わせることで、同等の品質を維持しつつコストを大幅に削減できることを記録した。コード生成にはコスト効率の高いGemini 3 Flashを、Agentic RAGには高精度のClaude OpusまたはGPT-5.2(Think)を組み合わせる構成が最適であることを確認した。
論文の構成
本論文の残りの部分は以下のように構成される。
第1章「関連研究」では、LLM評価ベンチマーク、コード生成、検索拡張生成、LLM-as-a-Judge評価方法論、マルチエージェントシステムに関する既存研究をレビューする。
第2章「システムアーキテクチャ」では、本研究の対象であるAI Checkの全体構造と各エージェントの役割を詳述する。自然言語―擬似コード変換エージェントの3段階逐次処理構造と、MFIDマッピングエージェントのRAGベース検索メカニズムを取り扱う。
第3章「実験設計」では、評価対象モデル、データセット構成、評価指標、コスト算定方法を説明する。コード生成データセット175サンプルとAgentic RAGデータセット93サンプルの特性を記述し、LLM-as-a-Judge評価基準を詳細に提示する。
第4章以降の実験結果・パイプライン最適化・結論は後編で取り扱います。
第1章 関連研究
本章では、LLM評価ベンチマーク、LLMベースのコード生成、検索拡張生成(RAG)、LLM-as-a-Judge評価方法論、マルチエージェントシステムに関する既存研究をレビューする。
LLM評価ベンチマーク
大規模言語モデルの性能を客観的に測定するためのベンチマークが開発されてきた。MMLU(Massive Multitask Language Understanding)は、57科目にわたる多肢選択問題を通じてモデルの知識と推論能力を評価する代表的なベンチマークであり、かつてはモデル間の弁別力が高かったものの、近年では90%以上の精度を達成するモデルが登場し、飽和現象を呈している。
HELM(Holistic Evaluation of Language Models)は、42のシナリオに対して精度、較正(calibration)、頑健性、公平性、偏り、毒性、効率性など7つの評価指標を適用する、最も包括的な学術ベンチマークと評価されている。BIG-Benchは442名の研究者が共同で設計した204の挑戦的課題を含み、多段階推論、隠喩解釈、心の理論(theory of mind)など、現行モデルの限界を試すタスクで構成されている。
コード生成分野ではHumanEvalが標準ベンチマークとして定着しており、数学的推論能力の評価にはGSM8Kが使用されている。近年ではGPQA、SuperGPQAなど博士課程レベルの知識を要求するベンチマークが登場したが、これらもわずか1年で高い性能を達成するモデルが現れ、ベンチマーク飽和の加速化現象が観察されている。
こうした静的ベンチマークの限界を克服するために、LiveBenchのような動的ベンチマークが提案された。動的ベンチマークは、継続的に新たな非公開データを活用することでデータ汚染(data contamination)問題の解決を目指している。Chatbot Arenaのような人間評価ベースのリーダーボードや、LLM-as-a-Judgeアプローチ(Alpaca Eval 2.0、Arena Hardなど)が、拡張性のある評価手法として台頭している。
LLMベースのコード生成
LLMを活用したコード生成研究は、OpenAIのCodexを先駆けとして発展してきた。CodexはGitHubの5,400万リポジトリから収集した159GBのPythonコードで学習され、GitHub Copilotの基盤となった。その後、StarCoderは80以上のプログラミング言語をサポートし、MetaのCodeLlamaはLlama 2をコード特化データセットでファインチューニングして開発された。
近年の研究は、LLMベースのコード生成の限界を深層的に分析している。「Where Do LLMs Still Struggle?」(2025)は、MBPP、HumanEval、BigCodeBench、LiveCodeBenchベンチマークにおいてClaude Sonnet-4、DeepSeek-V3、GPT-4oなどの主要モデルの失敗パターンを分析し、静的複雑性(static complexity)とプロンプトの誤解釈が繰り返される弱点であることを明らかにした。
テキスト―SQL変換分野においてもLLMの活用が活発である。Spider、WikiSQLなどのベンチマークが標準として使用されており、近年ではドメイン特化コード生成や低資源言語(low-resource language)に関する研究も進められている。給与システムや会計システムなど特定ドメインのルールをコードに変換する研究は、ドメイン知識とコード生成能力を同時に要求するという点で、独自の研究領域を形成している。
検索拡張生成(RAG)
検索拡張生成(Retrieval-Augmented Generation, RAG)は、LLMの幻覚(hallucination)問題を緩和し、最新情報へのアクセスを可能にする手法として台頭している。RAGは、ユーザーの質問に対してまず関連文書を検索した後、検索されたコンテキストをLLMに提供して応答を生成する方式で動作する。
Gupta et al.の包括的サーベイは、RAGのアーキテクチャ、検索―生成統合手法、拡張性およびバイアスの問題、今後の発展方向を体系的に整理した。近年では、単純な検索―生成パイプラインを超えてAgentic RAGが新たなパラダイムとして台頭している。Agentic RAGは、LLMエージェントがツール(tool)を活用して能動的に情報を検索・検証する方式であり、従来のRAGにおける受動的検索の限界を克服するものである。
Jayavardhana et al.(2025)は、BERTベースのクロスエンコーダとGPT-4を組み合わせたAgentic RAGシステムを提案し、学術相談分野における事実精度を向上させた。QuIM-RAGは、質問―質問逆索引マッチングという新たな検索メカニズムを導入し、多段階質問応答の推論性能を改善した。
RAGシステムの評価には、Recall@K、MRR(Mean Reciprocal Rank)、精度などの検索指標に加え、幻覚削減率、事実精度などが用いられる。Nguyen et al.(2024)の研究では、RAG適用時にLlama-3の精度が57.50%から81.50%に、GPT-4-turboは91.92%に向上したことを報告し、RAGの効果を実証した。
LLM-as-a-Judge評価方法論
伝統的な自然言語生成(NLG)の評価指標としては、BLEU、ROUGE、BERTScoreなどが使用されてきた。BLEU(Bilingual Evaluation Understudy)はn-gram精度に基づいて生成テキストと参照テキストの一致度を測定し、長さペナルティを適用して短い出力に対するバイアスを補正する。ROUGE-Lは最長共通部分列(LCS)を活用して構造的類似性を評価し、要約タスクにおいて使用される。BERTScoreはBERTの文脈的埋め込みを活用して意味的類似性を測定し、n-gramベースの指標よりも人間の判断との相関が高いことが示されている。
これらの伝統的指標は、コード生成や複雑な推論タスクにおいて意味的等価性を捉えるのに限界がある。これを受けて、LLM-as-a-Judgeパラダイムが新たな評価手法として台頭した。LLM-as-a-Judgeは、GPT-4やClaudeのような強力なLLMを評価者として活用し、生成結果の品質を判定する方式である。
「LLMs-as-Judges: A Comprehensive Survey」(2024)は、このパラダイムの機能性、方法論、応用、メタ評価、限界点を体系的に整理した。LLM-as-a-Judgeの主な利点としては、自然言語出力を通じた解釈可能性、タスクに対する汎化能力、大規模評価の拡張性が挙げられる。
LLM評価者のバイアス問題も指摘されている。位置バイアス(position bias)、モデル選好バイアス、プロンプト設計に応じた変動性などが再現性を阻害し得る。これを緩和するために、タスク特化の参照回答の提供、アンサンブル手法、Chain-of-Thought(CoT)プロンプティング、詳細な評価基準表(rubric)の設計などが推奨されている。
本研究では、LLM-as-a-Judge方式を適用し、4つの次元——構文正確性(Syntactic Correctness)、意味等価性(Semantic Equivalence)、条件完全性(Condition Completeness)、構造的類似性(Structural Similarity)——について各5点尺度で評価し、総点20点満点でコード生成品質を測定する。各次元に対して詳細な採点基準表を提供することで、評価の一貫性と再現性の確保を図った。
マルチエージェントシステムおよびパイプライン
LLMベースのマルチエージェントシステム(Multi-Agent System, MAS)は、複雑な問題を複数のエージェントの協業を通じて解決するアプローチである。ReActフレームワークは、推論(Reasoning)と行動(Acting)を交互に実行する方式により、エージェントがツールを活用してタスクを遂行できるようにした。その後、AutoGPT、LangChain Agentsなどのエージェントフレームワークが登場し、実用的な応用を可能にした。
「Large Language Model Based Multi-agents: A Survey of Progress」(IJCAI, 2024)は、LLMベースのマルチエージェントシステムの発展を包括的に整理した。このサーベイは、エージェントプロファイリング、通信方式、スキル開発、計画および推論の応用を取り扱い、単一エージェントからマルチエージェントへの進化過程を分析した。
MegaAgent(ACL Findings, 2025)は、事前定義された手順(SOP)なしに自律的に最大590のエージェントを生成し、ソフトウェア開発や社会シミュレーションなどの複雑なタスクを遂行するシステムを提案した。このシステムは、ベクトルデータベースを活用したメモリ検索とタスク分割を通じて、エージェント間の調整を実現している。
本研究の対象システムは、逐次エージェント(Sequential Agent)構造を採用している。自然言語―擬似コード変換エージェントの内部では、構造分析器、条件分析器、擬似コード生成器が逐次的に実行され、各段階の出力が次の段階の入力として渡される。MFIDマッピングエージェントはAgentTool方式で呼び出され、各用語に対してRAGベースの検索を実行する。このパイプライン構造において、各段階に適したモデルを選択することが、システム全体の性能に重要な影響を及ぼす。
研究の空白と本研究の位置づけ
既存研究をレビューした結果、以下の研究空白が確認される。
第一に、多段階パイプラインにおけるモデル選択研究の不在である。大半のLLM評価研究は単一タスクに対するモデル比較に集中しており、パイプライン構造において各段階に異なるモデルを使用する戦略に関する研究は不足している。
第二に、Thinking/Reasoningモードのタスク別効果分析の不在である。各プロバイダーは拡張推論モードを提供しているが、このモードがどのタスクにおいて効果的であるかに関する体系的な分析は限定的である。
第三に、安定性指標の不十分さである。既存の評価研究は品質指標に集中しており、空応答率やエラー発生率など、実際の運用環境において重要な安定性指標を看過する傾向がある。
第四に、ドメイン特化コード生成とAgentic RAGの統合評価の不在である。給与システムのような特定ドメインにおいて、コード生成とRAGを統合するパイプラインに対する評価研究は見当たらない。
本研究はこれらの空白を解消するために、日本の給与システムの実際のパイプラインを対象として、コード生成とAgentic RAGタスクに対する総合的なモデル比較評価を実施し、Thinkingモードのタスク別効果と安定性指標を分析することで、最適なパイプライン構成戦略を提示する。
第2章 システムアーキテクチャ
本章では、研究対象であるAI Checkの全体構造と各構成要素の役割を詳述する。まずシステムの概要とパイプライン構造を紹介した後、本研究において評価対象とした2つの中核エージェント——自然言語―擬似コード変換エージェントとMFIDマッピングエージェント——の動作方式を説明する。
システム概要
AI Checkは、給与担当者が自然言語(日本語)で記述した給与検査観点(CheckPoint)を、実行可能なSQLクエリへ自動変換するシステムである。このシステムは、ユーザーが複雑なSQL文法を知らなくとも、自然言語で検査条件を記述すれば、当該条件に合致する対象者をデータベースから抽出できるようにする。
一般的なText-to-SQLアプローチは自然言語を直接SQLに変換するが、本システムの対象データベースは300以上のテーブルと1,350以上のカラムで構成された大規模スキーマを有する。さらにカラム名がFPPAR03、FRPAP15のような内部コード(MFID)形式となっているため、LLMが自然言語から直接正確なSQLを生成することは困難である。こうした複雑性を解決するために、システムは問題を3つの段階に分離した。
すなわち、(1)自然言語をドメイン用語を含む擬似コードに変換し、(2)擬似コード内のドメイン用語をベクトル類似度検索に基づいてMFIDにマッピングした後、(3)MFIDがマッピングされた擬似コードを実行可能なSQLに変換する。
システムは図1に示すとおり、3つの主要エージェントで構成された多段階パイプライン構造を採用している。
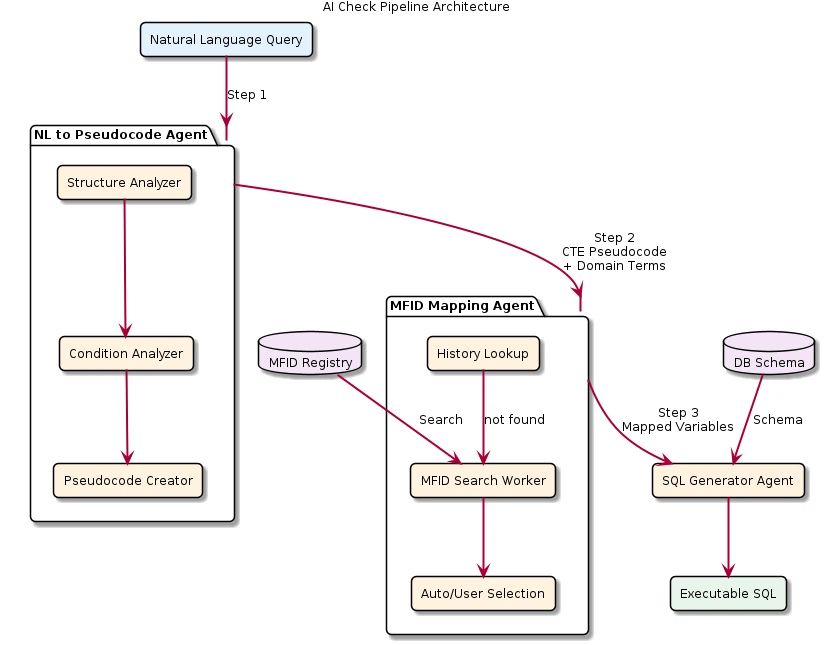
図1:AI Checkパイプライン構造
NL to Pseudocode Agent は、自然言語で記述された給与検査条件をSQL類似の擬似コードに変換する。この段階では、LLMのコード生成(Code Generation)能力が中核的に活用される。
MFID Mapping Agent は、擬似コードに含まれるドメイン用語(例:「入社年月日」、「固定部開始日」)を実際のデータベースフィールド識別子(MFID)にマッピングする。この段階では、ベクトル検索ベースのAgentic RAG方式が使用される。
Query Translation Agent は、MFIDがマッピングされた擬似コードを最終的な実行可能SQLクエリに変換する。この段階は比較的ルールベースの変換が主となるため、本研究の評価対象からは除外した。
本研究では、LLMの能力がシステム性能に直接的な影響を及ぼすNL to Pseudocode AgentとMFID Mapping Agentを評価対象として選定した。
NL to Pseudocode Agent
概要
NL to Pseudocode Agentは、自然言語で記述された給与検査観点をSQL類似の擬似コードに変換する役割を担う。日本の給与システムにおける複雑な業務ルール——雇用保険、健康保険、厚生年金、年末調整など——を正確にコードとして表現する必要があるため、LLMのドメイン理解力とコード生成能力が同時に求められる。
3段階逐次処理構造
このエージェントは、単一のLLM呼び出しではなく、3つのサブエージェントが逐次的に実行される構造を採用している。図2はこの3段階の処理フローを示す。
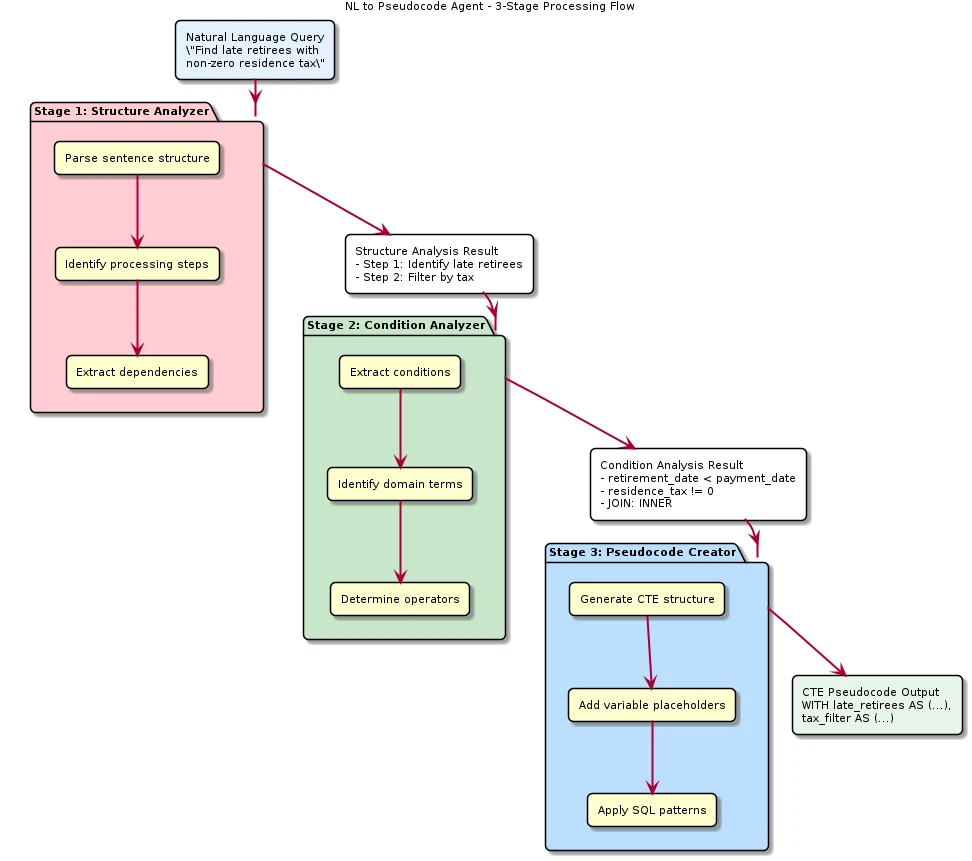
図2:NL to Pseudocode Agent — 3段階処理フロー
各段階は前段階の出力を入力として受け取り、段階的に変換を実行する。
(1)Structure Analyzer(構造分析器)
- 自然言語入力から対象者概念の階層構造を抽出する
- モード(trigger/anomaly/free)に応じて異なる処理アルゴリズムを適用する
- triggerモード:最上位の対象者概念と下位の対象者概念の階層関係を把握し、UNION ALLなどの結合関係を識別する
- anomalyモード:実行順序(1., 2., ...)を識別し、各順序の処理に適切な概念名を付与する
- 出力形式:「概念名」=「自然言語定義式」形式の構造化された定義
(2)Condition Analyzer(条件分析器)
- 構造化された自然言語定義式をSQL擬似コード条件式に変換する
- SELECT、FROM、WHERE句を擬似コード形式で構成する
- 主な変換ルール:
- すべての項目名は日本語で記述(システム必須項目を除く)
- 数値列の空値チェック:
COALESCE(列名, '0') = '0' - 文字列列の空値チェック:
COALESCE(列名, '') = '' - 論理演算子の変換:「かつ」→ AND、「または」→ OR
- 部分集合チェーン原則:概念Bが概念Aに依存する場合、FROM句で必ず概念Aを参照する
(3)Pseudocode Creator(擬似コード生成器)
- SQL擬似コード条件式をCTE(Common Table Expression)形式に構文変換する
- 条件式の内容は一切変更せず、構文スタイル(インデント、改行、AS句の配置)のみを整理する
- 最終出力:可読性が高く構造化されたCTE形式の擬似コード
入出力例
表1は、NL to Pseudocode Agentの実際の入出力例を示す。

表1:NL to Pseudocode Agent 入出力例
以下は、実際のシステムで処理された入出力例である。
入力(自然言語)
前月Payprocessに存在せず、当月Payprocessで初めて計算対象となった人(これを「入社者」とする)。
入社者の中から、固定部開始日と勤怠部開始日のうちより古い日付よりも前の退職年月日が登録されている人を過去退職者として特定する。入社者から過去退職者を除外した後、次のように分類する:
- 入社年月日が固定部開始日から固定部終了日の期間に含まれる場合 ⇒ 新規入社として処理
- 入社年月日が固定部開始日より前の場合 ⇒ 新規遅れ入社として処理
(1) Structure Analyzer出力 — 階層構造の抽出
- 入社者 = 前月Payprocessに存在せず、当月Payprocessで初めて計算対象となった人
- 過去退職者 = 入社者のうち、固定部開始日と勤怠部開始日のうちより古い日付よりも前の退職年月日が登録されている人
- 新規入社 = 入社者から過去退職者を除外した人のうち、入社年月日が固定部開始日から固定部終了日の期間に含まれる人
- 新規遅れ入社 = 入社者から過去退職者を除外した人のうち、入社年月日が固定部開始日よりも前の人
(2) Condition Analyzer出力 — SQL条件式変換
- 入社者 = SELECT payer_id, ..., 入社年月日, 固定部開始日, 固定部終了日, 勤怠部開始日, 退職年月日
FROM employee
WHERE pay_process = $当月Payprocess$
AND cal_process = $当月Payprocess$
AND (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM employee_prev);
- 過去退職者 = SELECT ... FROM 入社者
WHERE COALESCE(退職年月日, '') != ''
AND 退職年月日 < CASE WHEN 固定部開始日 < 勤怠部開始日
THEN 固定部開始日 ELSE 勤怠部開始日 END;
- 新規入社 = SELECT ..., '新規入社' as 入社種別 FROM 入社者
WHERE (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 BETWEEN 固定部開始日 AND 固定部終了日;
- 新規遅れ入社 = SELECT ..., '新規遅れ入社' as 入社種別 FROM 入社者
WHERE (payer_id, pay_number) NOT IN (SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 < 固定部開始日;
(3) Pseudocode Creator出力 — CTE形式変換
入社者 AS (
SELECT payer_id, calcu_labor_id, pay_number, emp_number,
pay_process, cal_process, 入社年月日, 固定部開始日,
固定部終了日, 勤怠部開始日, 退職年月日
FROM employee
WHERE pay_process = $当月Payprocess$
AND cal_process = $当月Payprocess$
AND (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM employee_prev)),
過去退職者 AS (
SELECT payer_id, calcu_labor_id, pay_number, emp_number,
pay_process, cal_process, 入社年月日, 固定部開始日,
固定部終了日, 勤怠部開始日, 退職年月日
FROM 入社者
WHERE COALESCE(退職年月日, '') != ''
AND 退職年月日 < CASE
WHEN 固定部開始日 < 勤怠部開始日 THEN 固定部開始日
ELSE 勤怠部開始日 END),
新規入社 AS (
SELECT *, '新規入社' as 入社種別
FROM 入社者
WHERE (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 BETWEEN 固定部開始日 AND 固定部終了日),
新規遅れ入社 AS (
SELECT *, '新規遅れ入社' as 入社種別
FROM 入社者
WHERE (payer_id, pay_number) NOT IN
(SELECT payer_id, pay_number FROM 過去退職者)
AND 入社年月日 < 固定部開始日)
出力される擬似コードは以下の特徴を有する。
- CTEベース構造 :WITH句のCTEを活用して段階的に対象者をフィルタリング
- 日本語―SQL混合 :テーブル名、カラム名に日本語を使用し、SQL文法と結合
- 論理的階層化 :入社者 → 過去退職者 → 新規入社/新規遅れ入社へと続く論理フロー
MFID Mapping Agent
概要
MFID Mapping Agentは、擬似コードに含まれるドメイン用語を実際のデータベースのフィールド識別子(MFID, Master Field ID)にマッピングする役割を担う。給与システムのデータベースには数千のフィールドが存在し、同一の概念を指す表現(例:「入社日」、「入社年月日」)を正確なMFIDにマッピングする必要がある。
MFIDデータ構造
MFIDは、給与システムデータベースの各フィールドを一意に識別する識別子であり、以下のメタデータとともに管理される。

表2:MFIDメタデータ構造
ベクトル検索インフラ
MFIDマッピングのために、システムはベクトル類似度検索ベースのRAGアーキテクチャを採用している。
ベクトルデータベース:PostgreSQL + pgvector拡張を使用する。pgvectorはPostgreSQLにベクトル類似度検索機能を追加するオープンソース拡張であり、既存のリレーショナルデータベースとの統合が容易で運用の複雑性が低いという利点がある。
埋め込みモデル:GoogleのGemini Embeddingモデル(gemini-embedding-001、2000次元)を使用する。埋め込みモデルの選定にあたり、以下の4つのモデルを比較評価した。
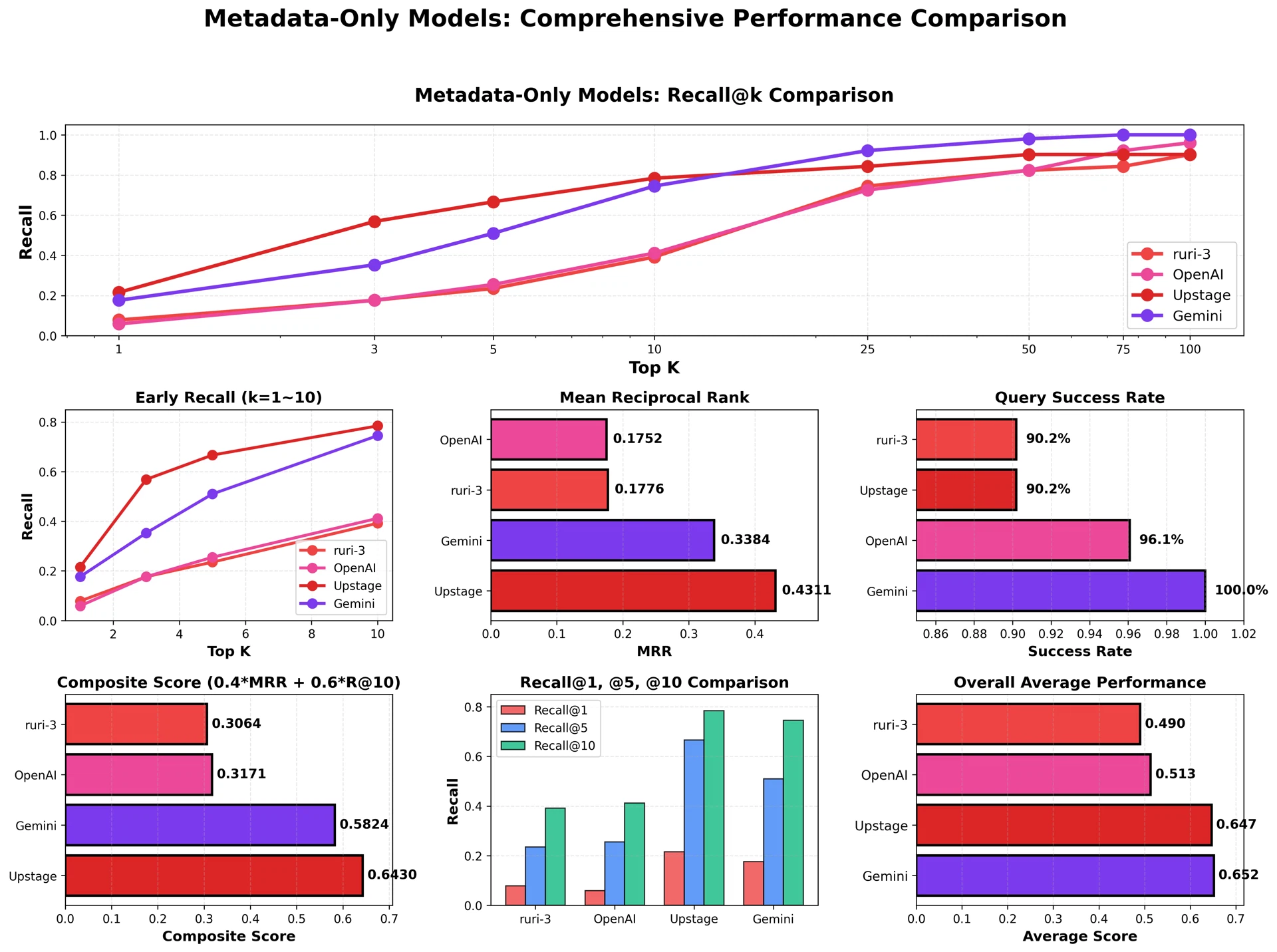
図3:埋め込みモデル別評価 — Composite Score = 0.4 × MRR + 0.6 × Recall@10
評価の結果、Upstage SolarがComposite Score基準で1位を記録したものの、APIがベータ版であり安定性が保証されていないため、プロダクション環境での使用には不適切であった。Recall@10で最高性能(80.4%)を示し、APIの安定性が確保されたGemini Embeddingを最終的に選定した。
Agentic RAGの動作方式
MFID Mapping Agentは、単純な検索―生成パイプラインではなく、Agentic RAG方式で動作する。図4はこのエージェントの全体フローを示す。
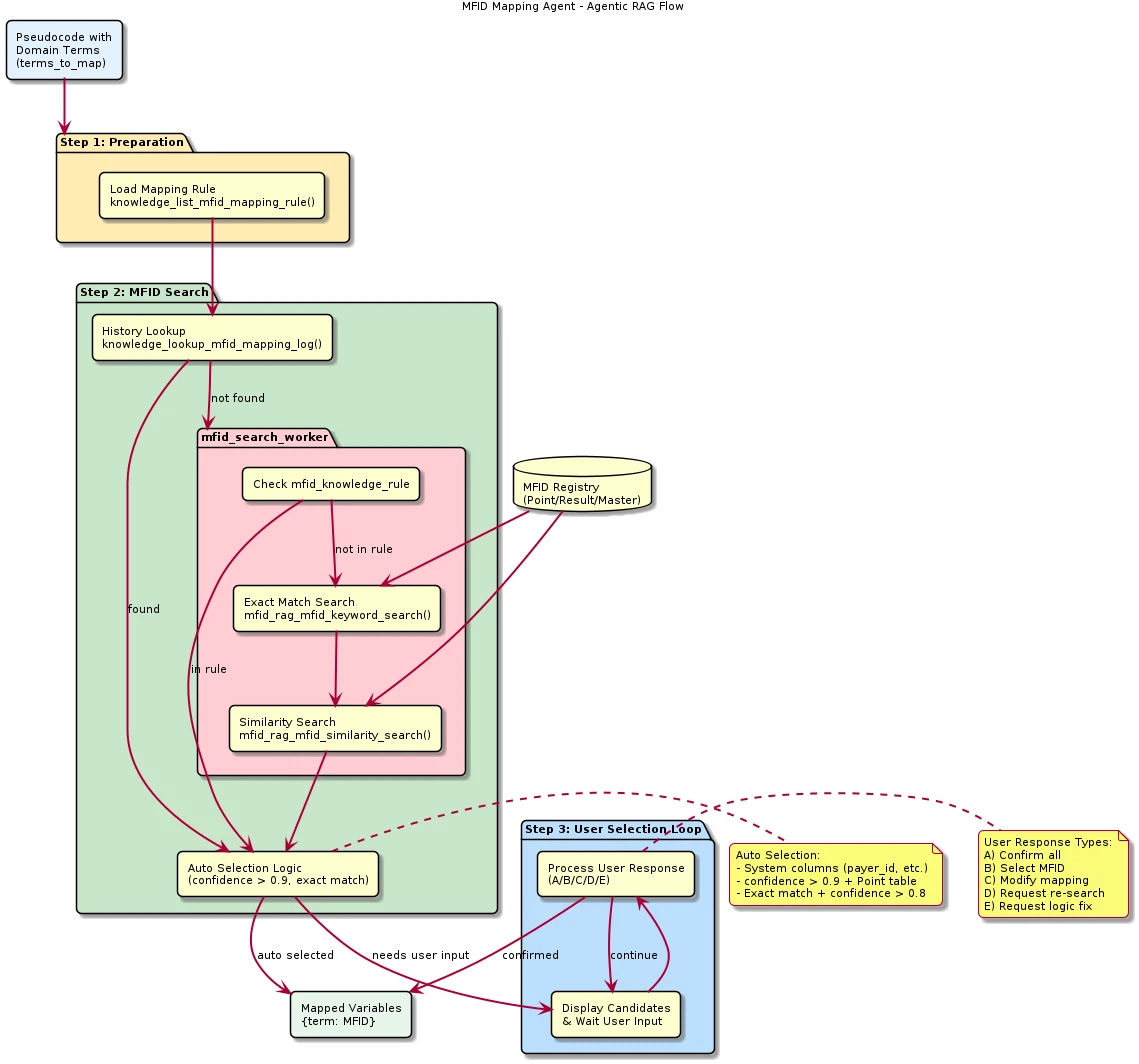
図4:MFID Mapping Agent — Agentic RAGフロー
LLMエージェントがツール(tool)を能動的に呼び出して必要な情報を検索し、検索結果を解釈して最適なマッピングを決定する。
この方式の中核的な特徴は以下のとおりである。
- 並列ツール呼び出し:複数の用語に対する検索を並列で実行し、処理時間を短縮
- コンテキスト認識選択:単純な類似度順位ではなく、カテゴリや給与タイプなどのコンテキストを考慮した選択
- 適応的検索:初回の検索結果が不十分な場合、追加検索を実行可能
評価対象および範囲
本研究では、以下の2つの理由からNL to Pseudocode AgentとMFID Mapping Agentを評価対象として選定した。
第一に、LLM依存度が高い段階であるためである。両エージェントはいずれもLLMの言語理解、推論、生成能力に大きく依存している。一方、Query Translation Agentはルールベースの変換が主であり、LLM選択による性能差が比較的小さい。
第二に、タスク特性が異なるためである。NL to Pseudocode Agentはコード生成(Code Generation)タスクであり、自然言語を構造化された擬似コードに変換する能力を要求する。MFID Mapping AgentはAgentic RAGタスクであり、ツール活用と検索結果の解釈能力を要求する。この異なるタスク特性は、同一のLLMであっても異なる性能を示し得ることを示唆しており、各段階に最適化されたモデル選択の必要性を提起する。

表3:評価対象タスク特性比較
小括
本章では、AI Checkの全体パイプライン構造と各構成要素を説明した。システムはNL to Pseudocode Agent、MFID Mapping Agent、Query Translation Agentの3段階で構成されており、本研究ではLLM依存度が高くタスク特性が異なる前者の2段階を評価対象として選定した。
NL to Pseudocode Agentは、structure_analyzer、condition_analyzer、pseudocode_creatorの3段階逐次処理構造により、自然言語をCTEベースの擬似コードに変換する。MFID Mapping Agentは、pgvectorベースのベクトル検索とGemini Embeddingモデルを活用したAgentic RAG方式により、ドメイン用語をMFIDにマッピングする。
次章では、これら2つのタスクに対する評価のための実験設計——評価対象モデル、データセット構成、評価指標——を詳述する。
第3章 実験設計
本章では、LLM比較評価のための実験設計を詳述する。評価対象モデル、データセット構成、評価指標、そしてコストおよび性能測定方法を説明する。
評価対象モデル
本研究では、3大主要LLMプロバイダー——Anthropic、Google、OpenAI——の13のモデル構成を評価対象として選定した。各プロバイダーは基本モデルとともに、拡張された推論能力を提供するThinking/Reasoningモードをサポートしており、本研究ではこの2つのモードをいずれも評価に含めた。
Claudeファミリー(Anthropic)
AnthropicのClaude 4.5シリーズは、Haiku、Sonnet、Opusの3つのティアで構成され、それぞれ速度―コスト―品質のトレードオフを提供する。Extended Thinkingモードは、複雑な推論タスクにおいてモデルがより深く思考できるようにする機能である。

表4:Claudeファミリーモデル
Geminiファミリー(Google)
GoogleのGeminiシリーズはFlashとProのティアに区分され、Flashは高速な応答速度を、Proは高い品質を目標とする。Thinkingモードは、推論過程を明示的に実行させる機能である。

表5:Geminiファミリーモデル
GPTファミリー(OpenAI)
OpenAIのGPTシリーズは5.2と5 Miniで構成される。Reasoningモード(o1系列)は、複雑な推論問題において段階的思考を実行するよう設計されている。
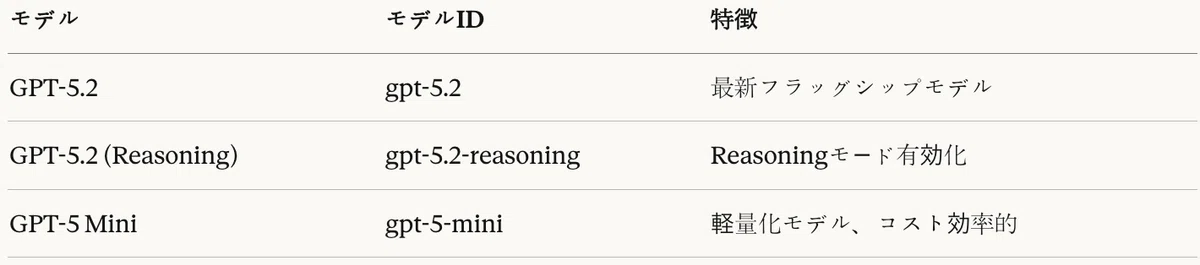
表6:GPTファミリーモデル
モデル構成の要約
表7は、全評価対象モデルを要約したものである。計13構成のうち、Claude 6種、Gemini 4種、GPT 3種で構成される。

表7:評価対象モデル要約
データセット構成
本研究では、2つのタスクに対してそれぞれ別個のデータセットを構成した。
コード生成データセット(CodeGen)
コード生成タスクの評価のために、実際のAI Checkシステムで使用されている給与検査観点175件を収集した。各サンプルは自然言語入力(日本語)と正解擬似コード(reference)で構成される。

表8:コード生成データセット特性
データセットは、給与システムの検査シナリオを含む。
- 入社/退職処理(入社、退職)
- 社会保険資格取得/喪失(資格取得、資格喪失)
- 給与計算異常値検出(給与計算異常)
- 年末調整関連検査(年末調整)
Agentic RAGデータセット(MFID Mapping)
Agentic RAGタスクの評価のために、ドメイン用語―MFIDマッピング93サンプルを構成した。各サンプルは擬似コードから抽出された用語と正解MFIDで構成される。
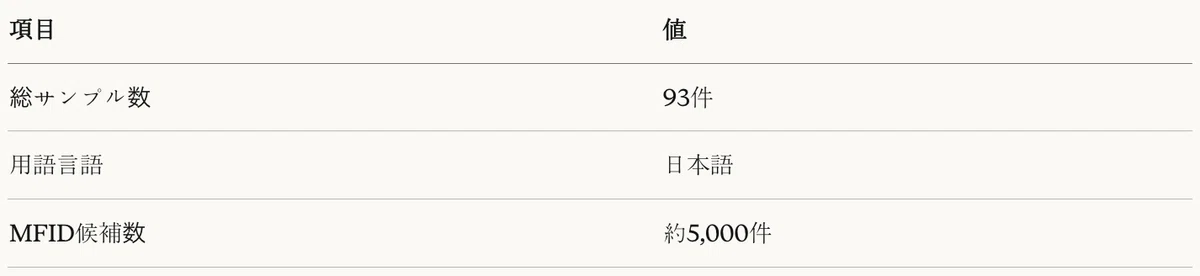
表9:Agentic RAGデータセット特性
評価指標
コード生成タスク評価指標
コード生成タスクに対して、伝統的テキスト類似度指標とLLM-as-a-Judgeベースの評価を併用した。
伝統的テキスト指標
BLEU(Bilingual Evaluation Understudy)
BLEUは、n-gram精度に基づいて生成テキストと参照テキストの一致度を測定する。
BLEU = BP × exp(Σ wₙ log pₙ)
ここでNは最大n-gramの次数(一般的に4)、wₙ = 1/Nは均等重み、pₙは修正n-gram精度である。長さペナルティ(Brevity Penalty)は、c > rの場合は1、c ≤ rの場合はe^(1-r/c)と定義される。(c:候補テキスト長、r:参照テキスト長)
ROUGE-L(Longest Common Subsequence)
ROUGE-Lは、最長共通部分列(LCS)に基づいてF1スコアを算出する。
ROUGE-L = (1 + β²) × R_LCS × P_LCS / (R_LCS + β² × P_LCS)
BERT-F1(BERTScore)
BERTScoreは、BERT埋め込みのコサイン類似度に基づいて意味的類似性を測定する。
F_BERT = 2 × (P_BERT × R_BERT) / (P_BERT + R_BERT)
LLM-as-a-Judge評価
伝統的指標の限界を補完するために、LLM-as-a-Judge方式を適用した。GPT-4を評価者として活用し、4つの次元において各5点満点、総計20点満点で評価する。
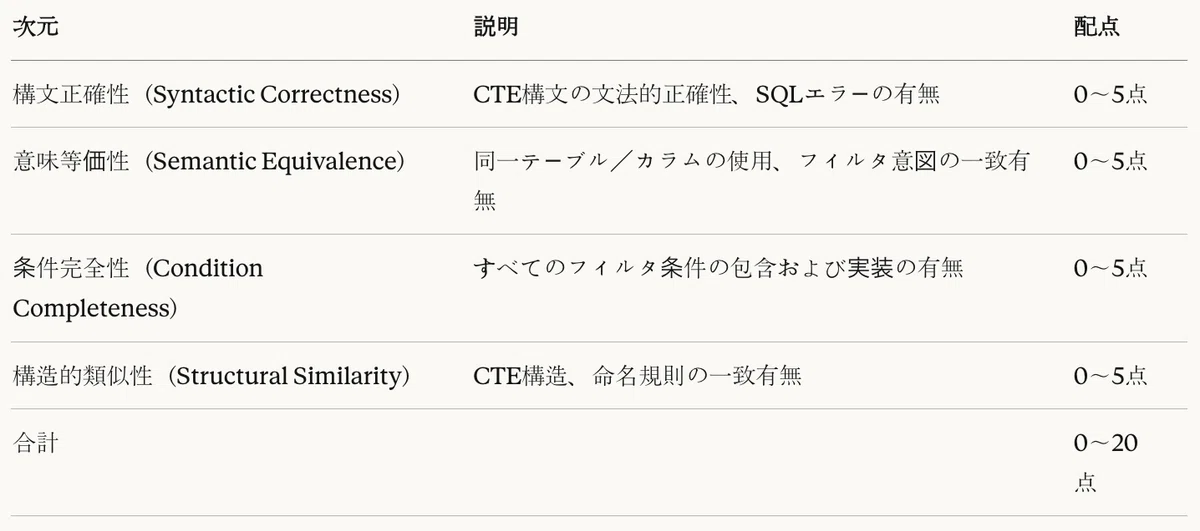
表10:LLM-as-a-Judge評価基準
Agentic RAGタスク評価指標
Agentic RAGタスクに対して、情報検索(Information Retrieval)分野の標準指標を適用した。
Recall@K
Recall@Kは、上位K件の検索結果内における正解の包含率を測定する。
Recall@K = |関連項目 ∩ 上位K項目| / |関連項目|
MRR(Mean Reciprocal Rank)
MRRは、正解の順位に対する逆数の平均を測定する。
MRR = (1/|Q|) × Σ (1/rank_q)
指標の正規化
すべての指標を0〜100%スケールに正規化し、比較可能とした。
- BLEU、ROUGE-L、BERT-F1:元の0〜1範囲 → ×100(%)
- LLM-as-a-Judge個別スコア:0〜5範囲 → ×20(%)
- LLM-as-a-Judge総点:0〜20範囲 → ×5(%)
- Recall@K、MRR:元の0〜1範囲 → ×100(%)
コストおよび性能指標
トークン価格
各プロバイダーのAPI価格ポリシーに基づいてコストを算定した。表11は1M(100万)トークンあたりのUSD価格を示す。
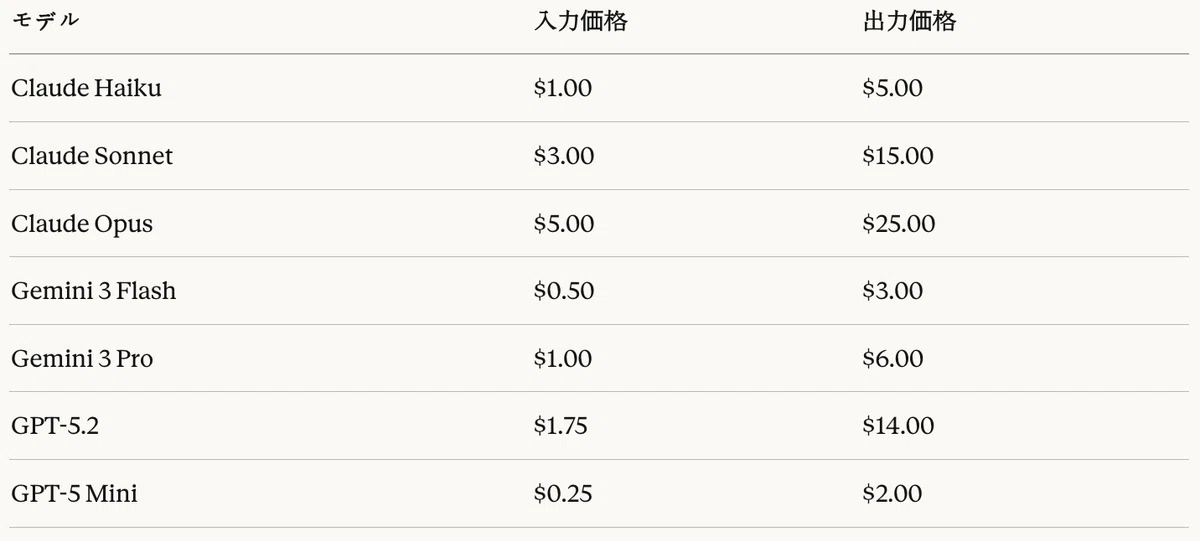
表11:モデル別トークン価格(USD per 1M tokens)
コスト効率性指標
品質とコストを同時に考慮するために、コスト効率性指標を定義した。
コスト効率性 = 品質スコア / コスト
- コード生成:LLM-as-a-Judge総点(%)/ 1Kリクエストあたりコスト($)
- Agentic RAG:MRR(%)/ 1Kリクエストあたりコスト($)
実験環境および設定
実験環境
- API呼び出し:各プロバイダーの公式APIを使用
- 並列処理:同時リクエスト数制限内で並列実行
- リトライ:APIエラー時に最大3回リトライ
- タイムアウト:リクエストあたり最大120秒
モデル設定
すべてのモデルに対して一貫した設定を適用した。

表12:モデル設定
Think/Reasoningモードの場合、各プロバイダーの推奨設定に従った。
- Claude Extended Thinking:thinking budget を適用
- Gemini Thinking:thinkingパラメータを有効化
- GPT Reasoning:reasoning_effort = "high"
小括
本章では、LLM比較評価のための実験設計を詳述した。13のモデル構成(Claude 6種、Gemini 4種、GPT 3種)を対象として、コード生成データセット175件とAgentic RAGデータセット93件に対して評価を実施する。
評価指標としては、コード生成タスクにBLEU、ROUGE-L、BERT-F1の伝統的指標と4次元LLM-as-a-Judge評価を適用し、Agentic RAGタスクにRecall@KとMRRを適用する。コスト分析のために各プロバイダーのトークン価格を基準に1Kリクエストあたりのコストを算定し、コスト効率性指標を通じて品質とコストのトレードオフを分析する。
次章では、コード生成タスクに対する実験結果を詳細に分析する。
📖 後編では、13モデルの実験結果(コード生成・Agentic RAG)、Thinkingモードの影響分析、安定性評価、コスト―品質トレードオフ、そして最適パイプライン構成戦略を詳しく取り扱います。
🚀 QueryPie AIを今すぐ体験する